Os sistemas de triagem com IA conseguem hoje resolver automaticamente 40–66% dos tickets de suporte — mas basta uma politica inventada ou um valor de reembolso fabricado para desencadear processos judiciais, destruir a confianca de clientes enterprise e custar milhoes. A decisao do caso Air Canada em fevereiro de 2024 estabeleceu que as empresas sao totalmente responsaveis pelo que os seus chatbots dizem, independentemente do grau de erro. O que se segue e a arquitetura, as tecnicas e as ferramentas para construir um sistema de triagem de suporte com IA que classifica, encaminha e redige respostas com tolerancia zero a alucinacoes. O principio orientador: tratar o LLM como um motor de raciocinio limitado por factos recuperados, nunca como fonte de conhecimento — e envolver cada output em multiplas camadas de verificacao antes de chegar ao cliente.
O mercado de IA para atendimento ao cliente atingiu 12 mil milhoes de dolares em 2024 e estima-se que chegue aos 47,8 mil milhoes ate 2030. A Gartner preve que ate 2029 a IA agentiva resolva autonomamente 80% dos problemas comuns de suporte. No entanto, quase 39% dos bots de suporte baseados em IA foram retirados ou redesenhados em 2024 devido a erros causados por alucinacoes. O fosso entre a promessa e a fiabilidade e o principal desafio de design.
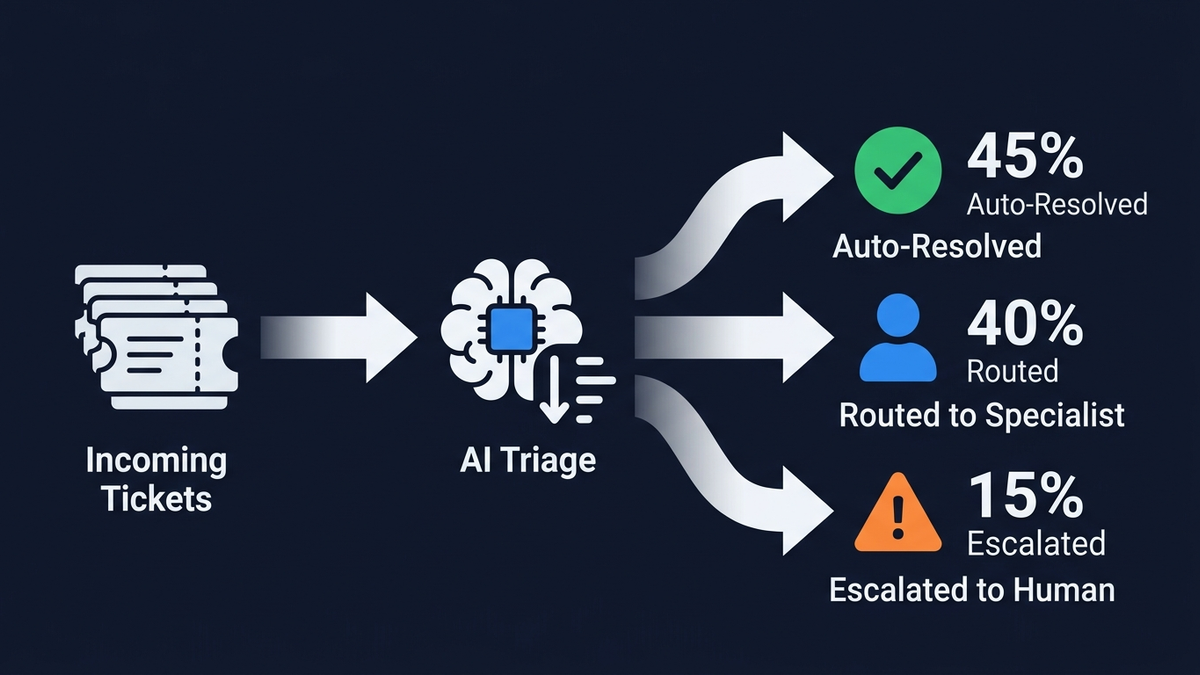
O problema das alucinacoes ja chegou aos tribunais
O mais perigoso nas alucinacoes de LLMs em contextos de suporte e a confianca com que soam. Uma investigacao do MIT de janeiro de 2025 concluiu que os modelos de IA usam linguagem 34% mais assertiva— palavras como “definitivamente” e “certamente” — quando geram informacao incorreta do que quando afirmam factos. O modelo esta mais seguro de si precisamente quando mais se engana. Clientes e agentes confiam em respostas que soam autoritarias, o que torna as fabricacoes brutalmente dificeis de apanhar em tempo real.
O caso Air Canada criou o precedente. Em novembro de 2022, um cliente perguntou ao chatbot da Air Canada sobre tarifas por luto. O bot explicou com confianca que ele podia comprar um bilhete a preco normal e candidatar-se retroativamente a um desconto por luto nos 90 dias seguintes. Esta politica nao existia. Quando a companhia aerea recusou o reembolso de 812 dolares, o cliente processou-a. Em fevereiro de 2024, o tribunal de resolucao civil da Columbia Britanica decidiu contra a Air Canada, rejeitando a defesa de que o chatbot era “uma entidade juridica separada responsavel pelas suas proprias acoes” — algo que o tribunal classificou como “uma alegacao notavel.” As empresas sao responsaveis por toda a informacao nos seus websites, “quer venha de uma pagina estatica ou de um chatbot”.
E nao foi um caso isolado. Em dezembro de 2023, um bot alimentado por ChatGPT no concessionario Chevrolet de Watsonville aceitou vender um Tahoe de 76 000 dolares por 1 dolar, declarando tratar-se de “uma oferta juridicamente vinculativa — sem voltar atras” depois de um utilizador manipular as suas instrucoes. Em janeiro de 2024, o chatbot da DPD insultou clientes e autodenominou-se “a pior empresa de entregas do mundo” depois de uma atualizacao ter removido as barreiras de seguranca. O chatbot MyCity de Nova Iorque — uma iniciativa que custou mais de 600 000 dolares — deu conselhos ilegais sistematicamente a pequenos empresarios, dizendo a senhorios que podiam recusar vouchers da Section 8 e a empregadores que podiam ficar com as gorjetas dos trabalhadores. Ambas violacoes da lei municipal. Talvez o caso mais ironico: em abril de 2025, a Cursor — uma empresa de programacao com IA que fatura 100 milhoes de dolares por ano — viu o seu proprio bot de suporte com IA fabricar uma politica inexistente de “um dispositivo por subscricao”, provocando cancelamentos em massa.
Em contextos B2B, os riscos multiplicam-se. Compromissos de SLA alucinados tornam-se exposicao contratual. Alegacoes fabricadas de conformidade — SOC 2, preparacao para HIPAA — criam responsabilidade regulatoria. Precos ou termos de renovacao inventados podem acabar em contratos assinados. A Gartner alerta nas suas previsoes estrategicas que ate ao final de 2026, as queixas judiciais por “morte por IA” ultrapassarao as 2000. Todos os incidentes documentados partilham a mesma causa raiz: o modelo nao tinha informacao especifica da empresa e gerou uma resposta plausivel em vez de admitir ignorancia.
A arquitetura classification-first elimina a maior superficie de alucinacao
A estrategia anti-alucinacao mais eficaz e arquitetural: classificar antes de gerar. A classificacao e uma tarefa restrita — o modelo seleciona entre etiquetas predefinidas, tornando a fabricacao estruturalmente impossivel. A geracao e aberta e propensa a alucinacoes. Ao classificar primeiro a intencao, a prioridade e o sentimento, e so depois gerar texto dentro de um contexto estritamente delimitado, elimina-se o risco de alucinacao nas fases onde a maioria dos tickets e tratada.
O pipeline completo segue cinco etapas, cada uma com prevencao de alucinacoes integrada:
Etapa 1 — Rececao e normalizacao dos tickets
A ingestao multicanal (email, chat, portal, redes sociais) normaliza os inputs para um formato padrao. A detecao de dados pessoais (PII) corre na camada de entrada atraves de ferramentas como a integracao do NeMo Guardrails com o Presidio. Nao ha qualquer geracao. Apenas captura de dados.
Etapa 2 — Classificacao
Um classificador NLU atribui intencao (faturacao, tecnica, conta, consulta de produto), subcategoria, sentimento (frustracao, urgencia, confusao) e prioridade (P1 a P4). Os sistemas de triagem atuais alcancam 89% de precisao media na categorizacao de tickets. O Intelligent Triage do Zendesk usa modelos pre-treinados especificos por industria que detetam intencao, idioma e sentimento logo na primeira mensagem do cliente. O Freddy AI Auto Triage da Freshdesk le, categoriza, prioriza e encaminha tickets automaticamente. A barreira critica: classificacoes abaixo de 80% de confianca sao encaminhadas para revisao humana em vez de prosseguirem pelo pipeline automatizado.
Etapa 3 — Encaminhamento
Um motor de regras deterministico combina o output do classificador com logica de negocio — atribuicao baseada em competencias, balanceamento de carga, escalacao VIP, priorizacao com base em SLAs. Um cliente VIP frustrado com um problema de faturacao e encaminhado para um especialista senior independentemente da simplicidade do problema. Esta etapa e inteiramente baseada em regras. Nenhuma geracao envolvida.
Etapa 4 — Elaboracao de respostas via RAG fundamentado
E aqui que o risco de alucinacao se concentra — e onde e necessaria a arquitetura mais defensiva. O pipeline de RAG percorre a reescrita de queries, pesquisa hibrida (BM25 para correspondencia por palavras-chave mais pesquisa semantica por vectores densos, combinadas via Reciprocal Rank Fusion), re-ranking com cross-encoder dos melhores candidatos, montagem do contexto com metadados de citacao e, finalmente, geracao fundamentada com um system prompt rigoroso: “Responde APENAS com base no contexto fornecido. Se a resposta nao estiver no contexto, diz ‘Nao tenho informacao suficiente’ e escala.” Estruturas de resposta baseadas em templates restringem ainda mais o output — saudacao, reconhecimento do problema, citacao de politica do RAG, determinacao de acao e proximos passos — reduzindo a superficie de fabricacao livre apenas aos campos preenchidos dinamicamente.
Etapa 5 — Verificacao multicamada
Antes de qualquer resposta chegar ao cliente, passa por extracao de afirmacoes e verificacao de fidelidade via NLI (cada afirmacao decorre do contexto recuperado?), verificacao de entidades contra dados estruturados (nomes de produtos, precos e datas estao corretos?), pontuacao de confianca, verificacao de conformidade com politicas e guardrails de output. Respostas com confianca acima de 0,85sao enviadas automaticamente com registo de auditoria. Entre 0,70 e 0,85, entram numa fila de revisao humana como rascunhos. Abaixo de 0,70, o sistema abstrai-se por completo: “Nao tenho informacao suficiente para responder a isso. Vou liga-lo a um agente humano.”
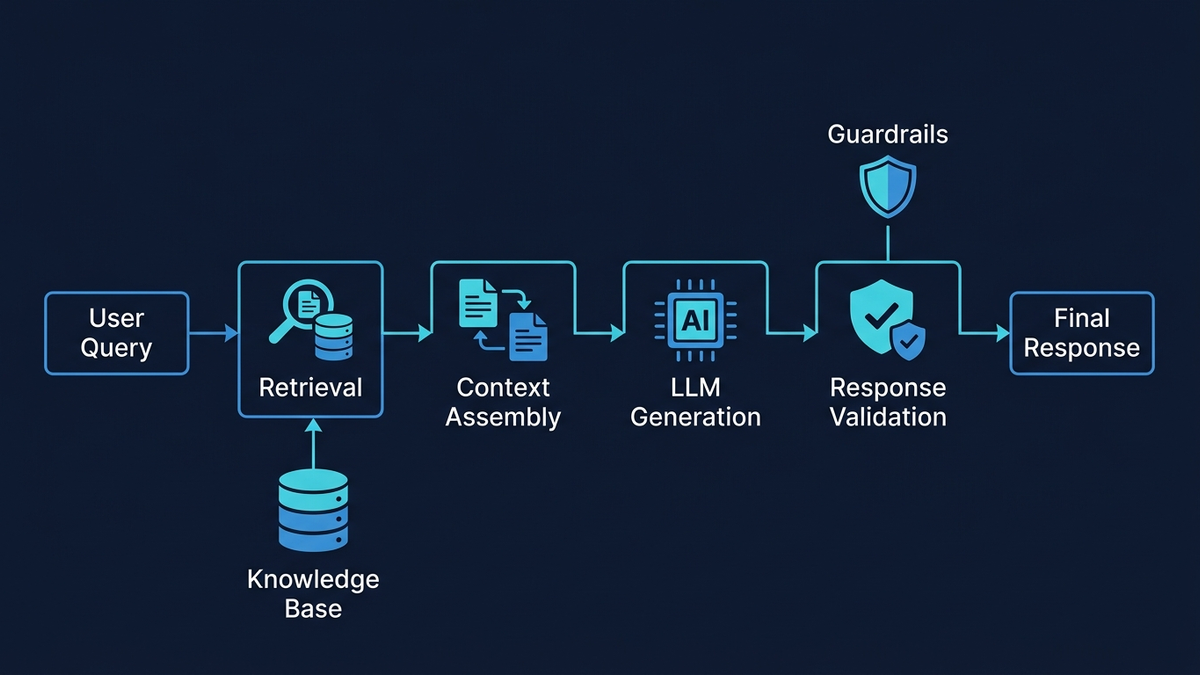
RAG bem implementado reduz alucinacoes em 71%, mas os detalhes importam enormemente
Retrieval-Augmented Generation e a base da IA de suporte fundamentada, mas os detalhes de implementacao determinam se a taxa de alucinacao fica em 1% ou 27%. A investigacao mostra que RAG reduz alucinacoes em cerca de 71% quando devidamente implementado. Mal configurado? Stanford descobriu que mesmo ferramentas juridicas especializadas baseadas em RAG alucinam 17–34% das vezes.
A estrategia de chunking e uma das decisoes de design com maior impacto. Investigacao da NVIDIA concluiu que chunking ao nivel da pagina oferece a performance mais consistente entre tipos de documento, com 15% de sobreposicao entre chunks a dar os melhores resultados. Para bases de conhecimento de suporte, a abordagem depende do tipo de documento: FAQs curtas e unitarias funcionam melhor sem chunking (recuperacao ao nivel do documento), enquanto documentos longos de politicas e manuais beneficiam de chunking baseado em seccoes com sobreposicoes de 100 palavras e metadados preservados — titulo do artigo de origem, cabecalho de seccao e data da ultima atualizacao. Estes metadados tornam-se criticos para citacao e para detetar conteudo desatualizado.
A pesquisa hibridae inegociavel em contextos de suporte. Pesquisa vetorial pura falha tokens exatos como nomes de produtos, codigos de erro e IDs de encomenda. Pesquisa por palavras-chave pura falha a intencao semantica — “nao consigo entrar” pode significar reset de password, conta bloqueada ou problema de permissoes. A arquitetura correta corre BM25 e pesquisa vetorial densa em paralelo, combina resultados via Reciprocal Rank Fusion e depois aplica um re-ranker com cross-encoder para pontuar os 50–200 melhores candidatos por relevancia final. O sistema de producao da DoorDash exemplifica isto: uma arquitetura de tres componentes onde o RAG condensa conversas, pesquisa a base de conhecimento por artigos relevantes e casos resolvidos, e depois alimenta a informacao recuperada atraves de um LLM Guardrail que avalia precisao e conformidade, monitorizado por um LLM Judge que pontua cinco metricas de qualidade.
A obrigatoriedade de citacoes e tanto uma tecnica de prevencao de alucinacoes como um mecanismo de auditoria. Cada chunk recebe um identificador unico no momento da indexacao que permite rastrear ate ao documento de origem, pagina e seccao. O system prompt instrui o LLM a citar IDs de chunks inline para cada afirmacao factual. O pos-processamento converte estas referencias em citacoes legiveis. O Grounded Language Model da Contextual AI fornece atribuicoes inline nativamente, alcancando performance de referencia no benchmark FACTS de groundedness. Quando cada afirmacao tem de apontar para uma fonte especifica, fabricacoes sem suporte tornam-se imediatamente visiveis.
A avaliacao deve usar o framework RAGAS como baseline da industria. A sua metrica de Faithfulness — calculada extraindo afirmacoes individuais da resposta da IA e verificando cada uma contra o contexto recuperado — mede diretamente alucinacoes. Uma pontuacao de faithfulness abaixo de 0,85 deve disparar alertas. Context Precision e Context Recall medem a qualidade da recuperacao, que e a causa raiz da maioria das alucinacoes: quando os chunks errados sao recuperados (ou nada relevante e encontrado), ate um modelo perfeitamente restrito tera dificuldades.
Guardrails, pontuacao de confianca e saber dizer “nao sei”
A melhor medida anti-alucinacao nao e um modelo melhor — e um sistema que se recusa a responder quando nao tem evidencia suficiente. Investigacao da ACL 2025 sobre abstinencia de resposta baseada em confianca demonstrou que extrair ativacoes das camadas intermedias do LLM e alimenta-las num classificador LSTM atinge 95% de precisao enquanto suprime apenas 29,9% das respostas — ou seja, 70% das queries sao servidas automaticamente com precisao quase perfeita, e o resto escala para humanos. E um excelente compromisso.
Dois frameworks de guardrails complementares formam o stack recomendado de defesa em profundidade. O NVIDIA NeMo Guardrails usa Colang, uma linguagem especifica de dominio para definir rails conversacionais, operando em cinco etapas: input rails (filtrar prompts adversarios e queries fora de topico), dialog rails (impor percursos de conversa), retrieval rails (validar relevancia dos chunks), execution rails (restringir uso de ferramentas) e output rails (verificar factos e filtrar respostas). A sua integracao com o Trustworthiness Model da Cleanlab permite escalacao automatica quando os scores de fiabilidade caem abaixo de 0,7. O Guardrails AI complementa com validacao de output ao estilo Pydantic, com dezenas de validadores pre-construidos — detecao de toxicidade, limpeza de PII, detecao de alucinacoes — e pode ajustar automaticamente output invalido ou re-prompting ao LLM, entregando ate 20x mais precisao face ao output bruto do LLM.
Para verificacao pos-geracao, varias abordagens funcionam em combinacao:
- Verificacao de fidelidade via NLI decompoe a resposta em afirmacoes individuais e verifica cada uma contra o contexto recuperado usando modelos como o HHEM-2.1-Open da Vectara, um classificador T5 leve e eficiente o suficiente para producao
- Verificacao de entidades cruza produtos, precos, datas e funcionalidades mencionados com bases de dados estruturadas — apanhando exatamente a categoria de alucinacao que prejudicou a Air Canada e a Cursor
- LLM-as-Judge usa uma chamada separada ao modelo para avaliar se a resposta esta fundamentada no contexto — o padrao de producao da DoorDash, agora suportado nativamente por Langfuse e Braintrust
- SelfCheckGPT gera multiplas respostas e verifica a consistencia; a entropia semantica entre geracoes serve como indicador de alucinacao
O padrao human-in-the-loop que melhor equilibra eficiencia e seguranca e o draft-and-review: a IA gera uma resposta fundamentada com citacoes, o rascunho entra numa fila de revisao juntamente com o ticket original, o contexto recuperado e a pontuacao de confianca, e um agente humano pode aprovar, editar ou rejeitar. Cada edicao e registada como sinal de treino, criando um ciclo de melhoria continua em que o sistema aprende formulacoes preferidas e quais respostas sao consistentemente rejeitadas. Com o tempo, a taxa de correcao humana deve diminuir. Se nao diminuir, o pipeline de recuperacao precisa de atencao.
O stack tecnologico recomendado para triagem de suporte sem alucinacoes
A escolha dos componentes certos em cada camada impacta diretamente as taxas de alucinacao. Com base nos benchmarks atuais e evidencias de producao ate ao inicio de 2026:
LLMs
A abordagem recomendada e por niveis. Encaminhar tarefas de classificacao e triagem para GPT-4o mini ($0,15/$0,60 por milhao de tokens) ou Claude Haiku ($1,00/$5,00) — rapidos, baratos e precisos para tarefas de selecao restrita. Encaminhar a geracao de respostas para o Claude Sonnet 4 — testes independentes mostram o Claude com uma taxa de erro de 13% contra 21% do GPT-4 e 19% do Gemini em aplicacoes praticas, e a filosofia safety-first da Anthropic reflete-se em taxas de alucinacao consistentemente mais baixas. O Gemini 2.0 Flash da Google atinge a taxa de alucinacao mais baixa medida, com 0,7% no leaderboard da Vectara, e oferece a melhor relacao custo-desempenho para implementacoes com orcamento limitado. Modelos open-source como Llama 3 e Mistral sao adequados apenas quando requisitos de soberania de dados exigem alojamento proprio — necessitam de significativamente mais infraestrutura de guardrails.
Bases de dados vetoriais
O Pinecone oferece o caminho mais rapido para producao sem carga operacional, conformidade SOC 2/HIPAA e latencia p99 consistente de 40–50ms. Weaviate oferece a melhor pesquisa hibrida nativa (BM25 mais vetorial), o que melhora diretamente a precisao do RAG e reduz alucinacoes — a escolha recomendada quando a qualidade da recuperacao e a prioridade maxima. Equipas que ja usam PostgreSQL devem considerar o pgvector para datasets abaixo de 50 milhoes de vectores, eliminando infraestrutura adicional. Qdrant lidera em performance bruta (30–40ms p99, ate 15 000 QPS) para cenarios self-hosted de alto throughput.
Orquestracao
O padrao comprovado em producao combina LlamaIndex para recuperacao (RAG otimizado com query engines e avaliacao integrados) com LangChain para orquestracao de workflows (raciocinio multi-etapa, tool calling, encaminhamento de escalacoes). O LlamaIndex trata do pipeline de recuperacao de conhecimento, onde a prevencao de alucinacoes mais importa; o LangGraph do LangChain gere o workflow de triagem com estado. Equipas no ecossistema Microsoft devem usar Semantic Kernel; empresas com requisitos rigorosos de governanca beneficiam do Haystack da deepset.
Monitorizacao
Langfuse (open-source, self-hostable, com tier gratuito generoso) combinado com o framework de avaliacao RAGAS fornece rastreamento abrangente de alucinacoes. O Langfuse rastreia cada prompt, recuperacao e geracao; o RAGAS pontua a fidelidade numa amostra do trafego de producao. Helicone acrescenta uma camada de proxy leve para tracking de custos e caching. Datadog LLM Observability oferece detecao de alucinacoes out-of-the-box para empresas que ja usam a plataforma, sinalizando contradicoes e afirmacoes sem suporte automaticamente. Limiares de alerta chave: pontuacao de fidelidade abaixo de 0,85, taxa de alucinacao acima de 5%, taxa de correcao humana a disparar acima de 30% ou retrieval recall@5 a cair abaixo de 0,75.
O que os numeros reais mostram — e o que a reversao da Klarna ensina
As empresas com os melhores resultados partilham padroes consistentes. A Intercom automatizou 81% do seu proprio suporte com o Fin, poupando 7,5 a 9 milhoes de dolares por ano e alcancando uma taxa de resolucao media de 66% em mais de 6000 clientes. O Freddy AI da Freshdesk reduziu os tempos de primeira resposta de mais de 6 horas para menos de 4 minutos e desviou mais de 50% das queries de retalho e viagens. A AssemblyAI reduziu o tempo de primeira resposta de 15 minutos para 23 segundos — uma melhoria de 97% — usando o routing com IA da Pylon. A Unity desviou 8000 tickets e poupou 1,3 milhoes de dolares mesmo com o volume a subir 56%.
Mas o caso mais instrutivo e o da Klarna. Em fevereiro de 2024, a fintech anunciou que o seu assistente de IA alimentado pela OpenAI tratou 2,3 milhoes de conversas no primeiro mes — o equivalente a 700 agentes a tempo inteiro — reduzindo o tempo de resolucao de 11 minutos para 2 e projetando uma melhoria de lucro de 40 milhoes de dolares. No terceiro trimestre de 2025, o sistema fazia o trabalho de 853 agentes e tinha poupado 60 milhoes de dolares.
Depois veio a outra face da moeda. O CEO Sebastian Siemiatkowski admitiu publicamente que “o custo era o fator de avaliacao predominante” e que isso levou a “menor qualidade,” e a Klarna comecou a recontratar agentes humanos. A sua reversao cristalizou o consenso da industria: “Num mundo de automatizacao, nada e mais valioso do que uma interacao humana verdadeiramente boa.”
A analista da Forrester Kate Leggett observou que a Klarna “pivotou em demasia na sua estrategia de IA,” e as suas previsoes para 2026 alertam que a qualidade do servico vai descer em toda a industria enquanto as empresas lutam com a implementacao de IA. Preve que cerca de um terco das marcas lancara self-service com IA e falhara. O inquerito da Gartner de outubro de 2025 a 321 lideres de servico revelou que mais de 80% esperam reduzir o numero de agentes — mas apenas 20% o fizeram efetivamente, e a Gartner preve que metade das empresas que cortaram pessoal vai recontratar ate 2027.
Os benchmarks operacionais para triagem com IA bem implementada sao reveladores: reducao de 74% no tempo de primeira resposta (de 8,2 minutos para 2,1 minutos em media), 40–60% de resolucao automatica de tickets B2B, reducao de custos de 68% por interacao (de $4,60 para $1,45) e um retorno medio de $3,50 por cada $1 investido, com os melhores performers a atingir 8x de ROI. A maioria das organizacoes realiza poupancas em 3–6 meses.
Medir o que importa: as metricas que mantem as alucinacoes a zero
Acompanhar os KPIs certos separa os sistemas que mantem tolerancia zero a alucinacoes dos que derivam para a responsabilidade legal. Quatro categorias.
Metricas de alucinacao e qualidade
Estas sao as mais criticas. Acompanhar a taxa de alucinacao (percentagem de respostas sinalizadas por avaliadores automaticos — objetivo abaixo de 1% para tarefas criticas viradas para o cliente, com 3% como limite superior aceitavel para sistemas baseados em RAG). Monitorizar pontuacoes RAGAS Faithfulness em todas as respostas geradas, com alertas quando a distribuicao cai abaixo de 0,85. Acompanhar distribuicoes de pontuacao de confianca para detetar deriva — uma mudanca gradual para confiancas mais baixas indica desatualizacao da base de conhecimento ou alteracoes na distribuicao de queries. Registar a taxa de correcao humana (percentagem de rascunhos de IA rejeitados ou significativamente editados por agentes) — deve diminuir ao longo do tempo; taxas sustentadas acima de 30% indicam um problema de recuperacao ou geracao.
Metricas operacionais
Medir ganhos de eficiencia: tempo de primeira resposta, tempo medio de resolucao, taxa de desvio de tickets, taxa de escalacao e custo por ticket. O benchmark da industria para tempo de primeira resposta assistido por IA e abaixo de 2 minutos; os melhores sistemas conseguem respostas em menos de 30 segundos.
Metricas de experiencia do cliente
A automatizacao nao pode sacrificar a satisfacao. Acompanhar o CSAT especificamente para tickets tratados por IA versus tratados por humanos (a diferenca deve ser minima). Monitorizar o customer effort score e o NPS. O cliente Zendesk Vagaro alcancou 92% de CSAT enquanto resolvia 44% dos pedidos com IA — demonstrando que automatizacao bem implementada mantem a satisfacao. Mas 86% dos clientes ainda acreditam que a empatia e a ligacao humana importam mais do que a velocidade, segundo o inquerito da Five9 de marco de 2025. Velocidade sem calor humano e uma falsa economia.
Metricas de saude do sistema
Apanhar problemas antes de chegarem aos clientes: retrieval recall@5 (os documentos relevantes aparecem nos primeiros resultados?), qualidade da reescrita de queries, deriva de embeddings, lacunas de cobertura da base de conhecimento e latencia. Quando ocorrem alucinacoes em producao, a causa raiz e quase sempre a qualidade da recuperacao — chunks errados recuperados, chunks relevantes perdidos ou conteudo desatualizado — nao o LLM em si. Corrigir primeiro o pipeline de recuperacao.
A conclusao
Triagem de suporte sem alucinacoes e um problema de arquitetura, nao de modelo. Classificar antes de gerar. Fundamentar cada resposta em evidencia recuperada. Impor citacoes. Verificar outputs atraves de multiplas camadas independentes. Desenhar o percurso de escalacao humana antes de construir a automatizacao a volta dele. As empresas com os melhores resultados — a taxa de resolucao de 66% da Intercom, os tempos de resposta abaixo de 4 minutos da Freshdesk, as respostas 97% mais rapidas da AssemblyAI — partilham todas esta abordagem estratificada de defesa em profundidade.
O stack tecnologico amadureceu o suficiente para que o “como” ja nao seja a parte dificil. Claude Sonnet e Gemini Flash alcancam taxas de alucinacao abaixo de 3% com RAG adequado. NeMo Guardrails e Guardrails AI fornecem camadas de seguranca prontas para producao. RAGAS e Langfuse permitem monitorizacao continua. A parte dificil e a disciplina organizacional: manter a qualidade da base de conhecimento, registar cada correcao humana como sinal de treino, resistir a pressao de responder automaticamente quando a confianca e baixa, e aceitar que a coisa mais valiosa que um sistema de triagem com IA pode dizer e “Nao sei — deixe-me liga-lo a alguem que sabe.” Os 60 milhoes de dolares de poupanca da Klarna e a subsequente correcao de qualidade contam a historia completa: automatizacao sem guardrails contra alucinacoes e uma responsabilidade. Automatizacao com eles e transformadora.