Les systèmes de triage IA peuvent désormais résoudre 40 à 66 % des tickets de support automatiquement — mais une seule politique inventée ou un montant de remboursement fabriqué suffit à déclencher des poursuites, saper la confiance de vos clients entreprise et coûter des millions. La décision Air Canada de février 2024 a posé le principe : les entreprises assument l'entière responsabilité juridique de ce que racontent leurs chatbots, aussi absurde que soit l'erreur. Ce qui suit détaille l'architecture, les techniques et les outils pour bâtir un système de triage IA qui classifie, achemine et rédige des réponses avec une tolérance zéro aux hallucinations. Le principe directeur : traitez le LLM comme un moteur de raisonnement contraint par des faits récupérés, jamais comme une source de connaissances — et enveloppez chaque sortie dans plusieurs couches de vérification avant qu'elle n'atteigne le client.
Le marché de l'IA pour le service client a atteint 12 milliards de dollars en 2024 et devrait franchir la barre des 47,8 milliards d'ici 2030. Gartner prévoit que d'ici 2029, l'IA agentique résoudra de manière autonome 80 % des problèmes courants de service client. Pourtant, près de 39 % des bots de service client alimentés par l'IA ont été retirés ou repris en 2024 à cause d'erreurs liées aux hallucinations. Le fossé entre la promesse de l'IA et sa fiabilité réelle est le défi central de conception.
Les hallucinations ne sont pas un risque théorique — elles sont déjà devant les tribunaux
Ce qui rend les hallucinations des LLM si dangereuses en contexte de support, c'est leur aplomb. Une étude du MIT de janvier 2025 a établi que les modèles d'IA emploient un langage 34 % plus péremptoire— des mots comme “définitivement” et “certainement” — lorsqu'ils génèrent des informations fausses que lorsqu'ils énoncent des faits avérés. Les clients et les agents font confiance aux réponses qui affichent de l'assurance, ce qui rend les fabrications redoutablement difficiles à détecter en temps réel.
L'affaire Air Canada fait désormais jurisprudence. En novembre 2022, un client interroge le chatbot de la compagnie sur les tarifs de deuil. Le bot lui explique avec assurance qu'il peut réserver un billet au tarif normal et demander rétroactivement une réduction de deuil sous 90 jours. Cette politique n'existait pas.Quand la compagnie refuse le remboursement de 812 $, le client porte l'affaire en justice. En février 2024, le Tribunal de résolution civile de la Colombie-Britannique tranche contre Air Canada, rejetant sa défense selon laquelle le chatbot était “une entité juridique distincte responsable de ses propres actions” — qualifiée de “soumission remarquable.” Le tribunal statue que les entreprises sont responsables de toutes les informations présentes sur leurs sites, “que l'information provienne d'une page statique ou d'un chatbot”.
Ce n'était pas un cas isolé. En décembre 2023, un bot alimenté par ChatGPT chez Chevrolet of Watsonville accepte de vendre un Tahoe à 76 000 $ pour 1 $, qualifiant l'opération de “offre juridiquement contraignante — pas de retour en arrière” après qu'un utilisateur a manipulé ses instructions. En janvier 2024, le chatbot de DPD insulte des clients et se décrit comme “la pire entreprise de livraison au monde” après qu'une mise à jour a supprimé les garde-fous. Le chatbot MyCity de New York — une initiative à plus de 600 000 $ — a donné systématiquement des conseils contraires à la loi aux petits entrepreneurs, expliquant aux propriétaires qu'ils pouvaient refuser les bons Section 8 et aux employeurs qu'ils pouvaient prélever les pourboires de leurs employés — deux infractions au droit municipal. Et le comble de l'ironie : en avril 2025, Cursor — une entreprise d'IA de codage qui génère 100 M$ de revenus annuels — a vu son propre bot de support inventer une politique inexistante de “un appareil par abonnement”, provoquant une vague de résiliations.
En B2B, les enjeux se démultiplient. Des engagements SLA inventés deviennent une exposition contractuelle. Des allégations de conformité fabriquées (SOC 2, conformité HIPAA) créent un risque réglementaire. Des tarifs ou conditions de renouvellement sortis de nulle part peuvent se retrouver dans des contrats signés. L'hypothèse de planification stratégique de Gartner avertit que d'ici fin 2026, les plaintes pour “mort par IA” dépasseront les 2 000. Le dénominateur commun de chaque incident documenté : le modèle manquait d'informations spécifiques à l'entreprise et a fabriqué une réponse vraisemblable plutôt que d'admettre son ignorance.
Classifier d'abord, générer ensuite : éliminer la plus grande surface d'hallucination
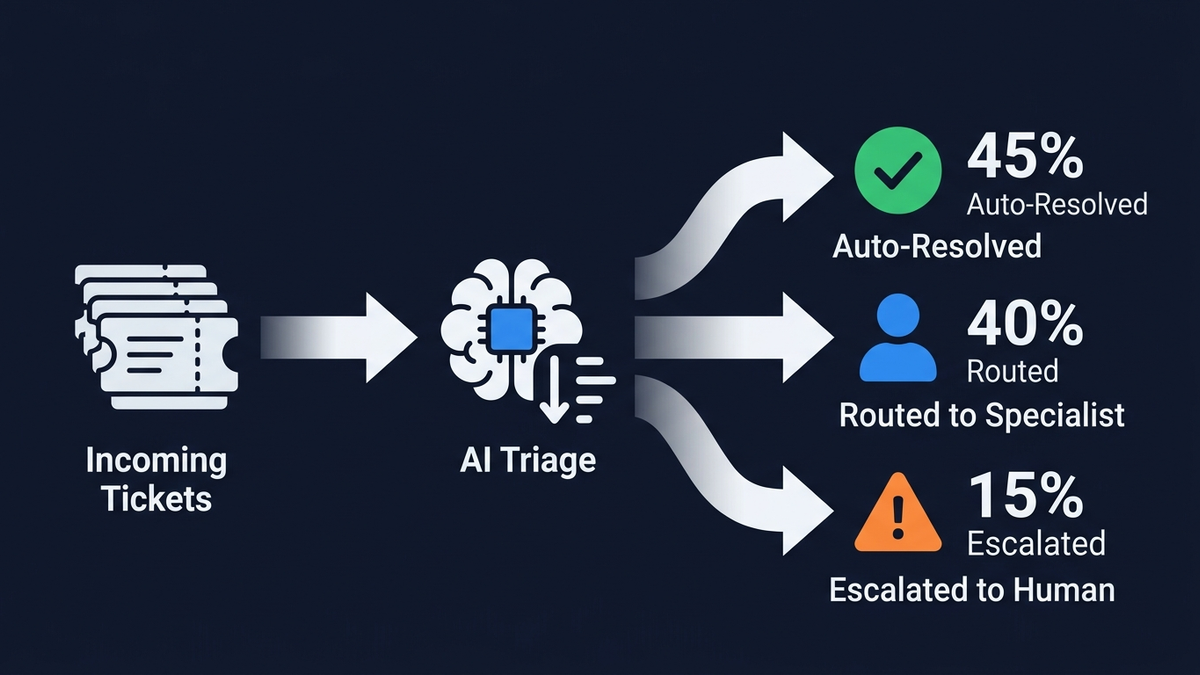
La stratégie anti-hallucination la plus puissante est architecturale : classifiez avant de générer.La classification est une tâche contrainte — le modèle sélectionne parmi des étiquettes prédéfinies, ce qui rend la fabrication structurellement impossible. La génération est libre et propice aux hallucinations. En classifiant d'abord l'intention, la priorité et le sentiment, puis en ne générant du texte qu'ensuite dans un périmètre étroitement délimité, vous supprimez le risque d'hallucination aux étapes où la majorité des tickets sont traités.
Le pipeline complet suit cinq étapes, chacune intégrant sa propre prévention des hallucinations :
Étape 1 — Réception et normalisation des tickets
L'ingestion multicanale (e-mail, chat, portail, réseaux sociaux) normalise les entrées dans un format standard. La détection des données personnelles intervient dès la couche d'entrée via des outils comme l'intégration Presidio de NeMo Guardrails. Aucune génération à ce stade — uniquement de la capture de données.
Étape 2 — Classification
Un classifieur NLU attribue l'intention (facturation, technique, compte, demande produit), la sous-catégorie, le sentiment (frustration, urgence, confusion) et la priorité (P1 à P4). Les systèmes de triage actuels atteignent 89 % de précision moyenne pour la catégorisation des tickets. Le Triage Intelligent de Zendesk utilise des modèles pré-entraînés par secteur qui détectent l'intention, la langue et le sentiment dès le premier message client. Freddy AI Auto Triage de Freshdesk lit, catégorise, priorise et achemine les tickets automatiquement. Point crucial : les seuils de confiance verrouillent la sortie — toute classification en dessous de 80 % de confiance est redirigée vers une revue humaine au lieu de continuer dans le pipeline automatisé.
Étape 3 — Acheminement
Un moteur de règles déterministe combine la sortie du classifieur avec la logique métier — affectation par compétences, équilibrage de charge, escalade VIP, priorisation tenant compte des SLA. Un client VIP frustré par un problème de facturation est orienté vers un spécialiste senior, quelle que soit la simplicité du problème. Cette étape repose entièrement sur des règles, sans aucune génération.
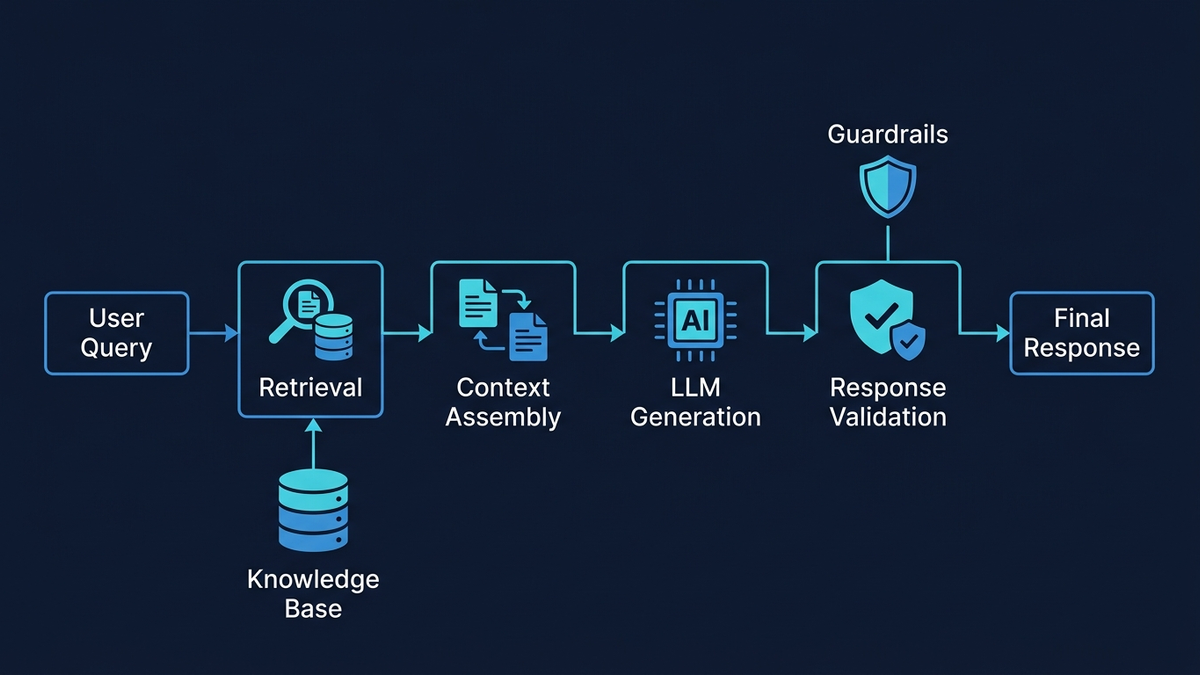
Étape 4 — Rédaction de réponses via RAG ancré
C'est ici que le risque d'hallucination se concentre, et où l'architecture doit être la plus défensive. Le pipeline RAG enchaîne réécriture de requête, recherche hybride (BM25 par mots-clés combiné à une recherche sémantique par vecteurs denses via Reciprocal Rank Fusion), reclassement par cross-encoder des meilleurs candidats, assemblage du contexte avec métadonnées de citation, et enfin génération ancrée avec un prompt système strict : “Répondez UNIQUEMENT en utilisant le contexte fourni. Si la réponse ne figure pas dans le contexte, dites ‘Je n'ai pas assez d'informations’ et escaladez.” Les structures de réponse basées sur des modèles contraignent davantage la sortie — salutation, accusé de réception, citation de politique issue du RAG, détermination de l'action et prochaines étapes — réduisant la surface de fabrication libre aux seuls champs remplis dynamiquement.
Étape 5 — Vérification multicouche
Avant qu'une réponse ne parvienne au client, elle passe par l'extraction des affirmations et la vérification de fidélité par NLI (chaque affirmation découle-t-elle du contexte récupéré ?), la vérification des entités par rapport aux données structurées (noms de produits, prix et dates corrects ?), le scoring de confiance, le contrôle de conformité aux politiques et les guardrails de sortie. Les réponses dépassant un score de 0,85sont envoyées automatiquement avec une piste d'audit. Entre 0,70 et 0,85, elles entrent dans une file de revue humaine en tant que brouillons. En dessous de 0,70, le système s'abstient : “Je n'ai pas assez d'informations pour répondre. Permettez-moi de vous mettre en relation avec un agent.”
Un RAG bien implémenté réduit les hallucinations de 71 %, mais le diable est dans les détails
Le Retrieval-Augmented Generation est le socle du support IA ancré, mais les détails d'implémentation font la différence entre un taux d'hallucination de 1 % et de 27 %. Les études montrent que le RAG réduit les hallucinations d'environ 71 % quand il est correctement implémenté, mais un système RAG mal configuré peut encore halluciner à des taux alarmants — Stanford a constaté que même des outils juridiques spécialisés basés sur le RAG hallucinent 17 à 34 % du temps.
La stratégie de découpage (chunking)est l'une des décisions de conception à plus fort impact. Les travaux de NVIDIA montrent que le découpage au niveau de la page offre les performances les plus régulières tous types de documents confondus, avec un chevauchement de 15 %entre segments pour des résultats optimaux. Pour les bases de connaissances de support, l'approche dépend du type de document : les FAQ courtes et mono-thématiques fonctionnent mieux sans découpage (récupération au niveau du document), tandis que les documents de politique longs et les manuels gagnent à être découpés par section avec des chevauchements de 100 mots et des métadonnées préservées — titre de l'article source, en-tête de section et date de dernière mise à jour. Ces métadonnées deviennent essentielles pour la citation et la détection de contenu obsolète.
La recherche hybrideest incontournable en contexte de support. La recherche vectorielle pure passe à côté des tokens exacts — noms de produits, codes d'erreur, identifiants de commande. La recherche par mots-clés pure rate l'intention sémantique : “je n'arrive pas à me connecter” peut renvoyer à une réinitialisation de mot de passe, un compte verrouillé ou un problème de permissions. L'architecture recommandée exécute BM25 et la recherche vectorielle dense en parallèle, combine les résultats via Reciprocal Rank Fusion, puis applique un reclasseur cross-encoder pour évaluer les 50 à 200 meilleurs candidats. Le système en production de DoorDash illustre cette approche : une architecture à trois composants où le RAG condense les conversations, recherche dans la base de connaissances les articles pertinents et les cas résolus, puis alimente les informations récupérées dans un LLM Guardrail qui évalue la précision et la conformité, le tout supervisé par un LLM Judge notant selon cinq métriques de qualité.
L'obligation de citationest à la fois une arme anti-hallucination et un mécanisme d'audit. Chaque segment reçoit un identifiant unique à l'indexation, traçable jusqu'à son document source, sa page et sa section. Le prompt système impose au LLM de citer les identifiants en ligne pour chaque affirmation factuelle. Le post-traitement les transforme en références lisibles. Le Grounded Language Model de Contextual AI fournit des attributions en ligne nativement, avec des performances à la pointe sur le benchmark FACTS d'ancrage. Quand chaque affirmation doit être rattachée à une source, les fabrications non étayées sautent aux yeux.
L'évaluation devrait s'appuyer sur le framework RAGAS comme référence sectorielle. Sa métrique de Fidélité — calculée en extrayant les affirmations individuelles de la réponse IA et en vérifiant chacune par rapport au contexte récupéré — mesure directement le taux d'hallucination. Un score de fidélité inférieur à 0,85 doit déclencher une alerte. La Précision du Contexte et le Rappel du Contexte mesurent la qualité de récupération, cause profonde de la majorité des hallucinations : quand les mauvais segments sont récupérés (ou que rien de pertinent ne remonte), même un modèle parfaitement contraint sera en difficulté.
Guardrails, score de confiance et l'art de dire “je ne sais pas”
La meilleure parade contre les hallucinations, ce n'est pas un modèle plus performant — c'est un système qui refuse de répondre quand les preuves manquent. Des travaux présentés à ACL 2025 sur l'abstinence de réponse basée sur la confiance ont démontré que l'extraction des activations des couches intermédiaires du LLM et leur passage dans un classifieur LSTM atteint une précision de 95 %tout en ne masquant que 29,9 % des réponses — autrement dit, 70 % des requêtes sont servies automatiquement avec une précision quasi parfaite, le reste étant escaladé vers des humains.
Deux frameworks de guardrails complémentaires forment la stratégie de défense en profondeur recommandée. NVIDIA NeMo Guardrailsutilise Colang, un langage dédié à la définition de rails conversationnels, opérant sur cinq niveaux : les rails d'entrée (filtrage des prompts adverses et requêtes hors sujet), les rails de dialogue (chemins de conversation imposés), les rails de récupération (validation de la pertinence des segments), les rails d'exécution (contraintes sur l'utilisation des outils) et les rails de sortie (vérification factuelle et filtrage des réponses). Son intégration avec le Modèle de Fiabilité de Cleanlab permet une escalade automatique dès que le score de fiabilité passe sous 0,7. Guardrails AIapporte une validation complémentaire de style Pydantic avec des dizaines de validateurs prêts à l'emploi — détection de toxicité, suppression des données personnelles, détection des hallucinations — et peut automatiquement corriger les sorties non conformes ou relancer le LLM, offrant jusqu'à 20 fois plus de précision par rapport à la sortie brute du LLM.
Pour la vérification post-génération, plusieurs approches se combinent efficacement :
- Vérification de fidélité par NLI: décompose la réponse en affirmations individuelles et vérifie chacune par rapport au contexte récupéré à l'aide de modèles comme HHEM-2.1-Open de Vectara, un classifieur T5 léger suffisamment efficace pour la production
- Vérification des entités : croise les produits, prix, dates et fonctionnalités mentionnés avec des bases de données structurées — c'est ce type d'hallucination qui a causé les incidents Air Canada et Cursor
- LLM-as-Judge: un appel de modèle distinct évalue si la réponse est ancrée dans le contexte — le schéma en production de DoorDash, désormais supporté nativement par Langfuse et Braintrust
- SelfCheckGPT: génère plusieurs réponses et vérifie leur cohérence ; l'entropie sémantique entre les générations sert d'indicateur d'hallucination
Le schéma de validation humaine qui concilie le mieux efficacité et sécurité est le brouillon puis relecture: l'IA génère une réponse ancrée avec citations, le brouillon entre dans une file de revue accompagné du ticket original, du contexte récupéré et du score de confiance, et un agent humain peut approuver, modifier ou rejeter. Chaque modification est enregistrée comme signal d'entraînement, créant une boucle d'amélioration continue où le système apprend les formulations préférées et identifie les réponses systématiquement rejetées. Au fil du temps, le taux de correction humaine devrait baisser — s'il stagne, c'est le pipeline de récupération qui mérite votre attention.
Le stack technique recommandé pour un triage sans hallucination
Le choix des bons composants à chaque couche impacte directement les taux d'hallucination. Voici les recommandations fondées sur les benchmarks et les retours de production jusqu'au début 2026 :
LLM
Adoptez une approche par paliers. Orientez les tâches de classification et de triage vers GPT-4o mini (0,15 $/0,60 $ par million de tokens) ou Claude Haiku(1,00 $/5,00 $) — rapides, économiques et précis pour les tâches de sélection contraintes. Réservez la génération de réponses à Claude Sonnet 4 — des tests indépendants situent Claude à un taux d'erreur de 13 % contre 21 % pour GPT-4 et 19 % pour Gemini en applications réelles, et la philosophie de conception “sécurité d'abord” d'Anthropic se traduit par des taux d'hallucination systématiquement plus bas. Le Gemini 2.0 Flashde Google affiche le taux d'hallucination le plus faible mesuré, à 0,7 %sur le classement de Vectara, avec le meilleur rapport coût-performance pour les déploiements soucieux du budget. Les modèles open source comme Llama 3 et Mistral ne se justifient que lorsque les exigences de souveraineté des données imposent l'hébergement interne — ils nécessitent une infrastructure de guardrails nettement plus conséquente.
Bases de données vectorielles
Pinecone offre le chemin le plus rapide vers la production sans charge opérationnelle, conformité SOC 2/HIPAA et une latence p99 constante de 40 à 50 ms. Weaviate propose la meilleure recherche hybride native (BM25 + vectorielle), ce qui améliore directement la précision du RAG et réduit les hallucinations — le choix à privilégier quand la qualité de récupération est votre priorité absolue. Les équipes déjà sur PostgreSQL devraient envisager pgvector pour les jeux de données de moins de 50 millions de vecteurs, éliminant toute infrastructure supplémentaire. Qdrant domine en performance brute (30 à 40 ms p99, jusqu'à 15 000 QPS) pour les scénarios auto-hébergés à haut débit.
Orchestration
Le schéma éprouvé en production combine LlamaIndex pour la récupération (RAG optimisé avec moteurs de requêtes et d'évaluation intégrés) et LangChainpour l'orchestration des workflows (raisonnement multi-étapes, appel d'outils, routage des escalades). LlamaIndex gère le pipeline de récupération des connaissances là où la prévention des hallucinations est la plus critique ; le LangGraph de LangChain pilote le workflow de triage à état. Les équipes orientées Microsoft devraient utiliser Semantic Kernel ; les entreprises soumises à des exigences strictes de gouvernance tireront parti de Haystack par deepset.
Monitoring
Langfuse (open source, auto-hébergeable, offre gratuite généreuse) combiné au framework d'évaluation RAGAS offre un suivi complet des hallucinations. Langfuse trace chaque prompt, récupération et génération ; RAGAS évalue la fidélité sur un échantillon du trafic de production. Helicone ajoute une couche proxy légère pour le suivi des coûts et la mise en cache. Datadog LLM Observability fournit une détection des hallucinations prête à l'emploi pour les entreprises déjà sur la plateforme, signalant automatiquement contradictions et affirmations non étayées. Seuils d'alerte clés : score de fidélité inférieur à 0,85, taux d'hallucination dépassant 5 %, taux de correction humaine au-delà de 30 %, ou rappel de récupération@5 passant sous 0,75.
Ce que montrent les chiffres — et ce que le revirement de Klarna nous apprend
Les entreprises qui obtiennent les meilleurs résultats avec le triage IA partagent des schémas cohérents. Intercom a automatisé 81 % de son propre support avec Fin, économisant 7,5 à 9 millions de dollars par an et atteignant un taux de résolution moyen de 66 % auprès de plus de 6 000 clients. Freddy AI de Freshdesk a fait passer le temps de première réponse de plus de 6 heures à moins de 4 minutes et a dévié plus de 50 % des requêtes retail et voyage. AssemblyAIa réduit le temps de première réponse de 15 minutes à 23 secondes — une amélioration de 97 % — grâce au routage IA de Pylon. Unity a dévié 8 000 tickets et économisé 1,3 million de dollars alors que le volume grimpait de 56 %.
Le cas le plus instructif reste celui de Klarna. En février 2024, la fintech annonce que son assistant IA alimenté par OpenAI a traité 2,3 millions de conversations dès le premier mois — l'équivalent de 700 agents à temps plein — réduisant le temps de résolution de 11 à 2 minutes et projetant un gain de 40 M$ sur le résultat. Au troisième trimestre 2025, le système remplaçait le travail de 853 agentset avait permis d'économiser 60 millions de dollars. Mais le PDG Sebastian Siemiatkowski a reconnu publiquement que “le coût était le critère d'évaluation prédominant,” ce qui avait conduit à “une qualité inférieure.” Klarna a alors commencé à réembaucher des agents humains. Son mea culpa a cristallisé le consensus du secteur : “Dans un monde d'automatisation, rien n'a plus de valeur qu'une interaction humaine véritablement exceptionnelle.”
L'analyste Forrester Kate Leggett a estimé que Klarna avait “poussé trop loin son virage IA.” Ses prédictions pour 2026 avertissent que la qualité de service va reculer dans tout le secteur tandis que les entreprises se débattent avec la complexité du déploiement IA. Elle anticipe que environ un tiers des marques déploieront un self-service IA et échoueront. L'enquête d'octobre 2025 de Gartner auprès de 321 responsables de service révèle que plus de 80 % prévoient de réduire leurs effectifs d'agents — mais seuls 20 % l'ont fait, et Gartner prédit que la moitié des entreprises qui ont réduit leurs équipes réembaucheront d'ici 2027.
Les benchmarks opérationnels d'un triage IA bien conçu dressent un tableau clair de ce qui est atteignable : réduction de 74 % du temps de première réponse (de 8,2 minutes à 2,1 minutes en moyenne), 40 à 60 % de résolution automatique des tickets B2B, réduction des coûts de 68 % par interaction (de 4,60 $ à 1,45 $), et un retour moyen de 3,50 $ pour chaque dollar investi, les meilleurs atteignant un ROI de 8x. La plupart des organisations dégagent des économies sous 3 à 6 mois.
Mesurer ce qui compte : les métriques qui gardent les hallucinations à zéro
Suivre les bons KPI fait la différence entre un système qui maintient une tolérance zéro aux hallucinations et un système qui dérive vers le risque juridique. Les métriques se répartissent en quatre familles :
Hallucination et qualité
Ce sont les métriques reines. Suivez le taux d'hallucination (pourcentage de réponses signalées par les évaluateurs automatisés — cible sous 1 %pour les tâches critiques côté client, avec 3 % comme plafond acceptable pour les systèmes RAG). Surveillez les scores de Fidélité RAGAS sur l'ensemble des réponses générées, avec alerte dès que la distribution passe sous 0,85. Pistez les distributions de scores de confiance pour détecter les dérives — un glissement progressif vers des scores plus bas trahit un vieillissement de la base de connaissances ou un changement dans la distribution des requêtes. Enregistrez le taux de correction humaine (pourcentage de brouillons IA rejetés ou fortement modifiés par les agents) — il doit baisser au fil du temps ; s'il reste au-dessus de 30 %, c'est un signal d'alarme sur la récupération ou la génération.
Métriques opérationnelles
Mesurez les gains d'efficacité : temps de première réponse, temps moyen de résolution, taux de déviation des tickets, taux d'escalade et coût par ticket. La référence sectorielle pour le temps de première réponse assisté par IA est inférieure à 2 minutes ; les systèmes les plus performants répondent en moins de 30 secondes.
Expérience client
Veillez à ce que l'automatisation ne sacrifie pas la satisfaction. Suivez le CSAT séparément pour les tickets traités par l'IA et ceux traités par des humains (l'écart devrait être minime). Surveillez le score d'effort client et le NPS. Vagaro, client de Zendesk, a atteint un CSAT de 92 % tout en résolvant 44 % des demandes avec l'IA — la preuve qu'une automatisation bien conçue préserve la satisfaction. Mais 86 % des clientsestiment toujours que l'empathie et le contact humain comptent davantage que la rapidité, selon l'enquête Five9 de mars 2025. La rapidité sans chaleur humaine est une fausse économie.
Santé du système
Détectez les problèmes avant qu'ils n'atteignent les clients : rappel de récupération@5 (les documents pertinents apparaissent-ils dans les premiers résultats ?), qualité de la réécriture de requête, dérive des embeddings, lacunes de couverture de la base de connaissances et latence. Quand des hallucinations surviennent en production, la cause profonde est presque toujours la qualité de la récupération — mauvais segments récupérés, segments pertinents manqués ou contenu obsolète — et non le LLM lui-même. Commencez toujours par le pipeline de récupération.
L'essentiel
Le triage IA sans hallucination est un problème d'architecture, pas de modèle. Classifiez avant de générer. Ancrez chaque réponse dans des preuves récupérées. Imposez les citations. Vérifiez les sorties via plusieurs couches indépendantes. Concevez le chemin d'escalade humaine avant de construire l'automatisation autour. Les entreprises qui obtiennent les meilleurs résultats — le taux de résolution de 66 % d'Intercom, les réponses en moins de 4 minutes de Freshdesk, les premières réponses 97 % plus rapides d'AssemblyAI — partagent toutes cette approche multicouche de défense en profondeur.
Le stack technique a suffisamment mûri pour que le “comment” ne soit plus le problème. Claude Sonnet et Gemini Flash atteignent des taux d'hallucination inférieurs à 3 % avec un RAG bien configuré. NeMo Guardrails et Guardrails AI fournissent des couches de sécurité prêtes pour la production. RAGAS et Langfuse assurent le monitoring continu. Ce qui reste difficile, c'est la discipline organisationnelle : maintenir la qualité de la base de connaissances, enregistrer chaque correction humaine comme signal d'entraînement, résister à la tentation de répondre automatiquement quand la confiance est basse, et accepter que la chose la plus utile qu'un système de triage IA puisse dire est “Je ne sais pas — laissez-moi vous mettre en relation avec quelqu'un qui saura vous aider.” Les 60 millions d'économies de Klarna et sa correction de cap ultérieure racontent toute l'histoire : l'automatisation sans guardrails anti-hallucination est un passif. L'automatisation avec eux change la donne.