Los sistemas de triaje con IA ya resuelven automáticamente entre el 40 y el 66 % de los tickets de soporte. Pero una sola política inventada o un monto de reembolso fabricado puede desencadenar demandas, pulverizar la confianza empresarial y costar millones. El fallo de Air Canada de febrero de 2024 lo dejó negro sobre blanco: las empresas asumen la responsabilidad legal total por lo que dicen sus chatbots, sin importar lo disparatado que sea. A continuación se detalla la arquitectura, las técnicas y las herramientas para construir un sistema de triaje de soporte con IA que clasifique, enrute y redacte respuestas con tolerancia cero a las alucinaciones. La idea de fondo: tratar al LLM como un motor de razonamiento restringido por hechos recuperados, nunca como una fuente de conocimiento — y envolver cada salida en múltiples capas de verificación antes de que llegue al cliente.
El mercado de atención al cliente con IA alcanzó 12.000 millones de dólares en 2024 y se proyecta que llegue a 47.800 millones para 2030. Gartner pronostica que para 2029, la IA agéntica resolverá de forma autónoma el 80 % de los problemas comunes de servicio. Sin embargo, cerca del 39 % de los bots de atención al cliente con IA fueron retirados o rediseñados en 2024 debido a errores de alucinación. Esa brecha entre la promesa y la fiabilidad es el desafío de diseño central.
El problema de las alucinaciones no es teórico — ya está en los tribunales
Lo más peligroso de las alucinaciones de los LLM en contextos de soporte es su aplomo. Una investigación del MIT de enero de 2025 encontró que los modelos de IA usan un 34 % más de lenguaje asertivo— palabras como “definitivamente” y “ciertamente” — al generar información incorrecta que al enunciar hechos reales. El modelo está más seguro de sí mismo justo cuando más se equivoca. Clientes y agentes confían en respuestas que suenan autoritativas, lo que hace que las fabricaciones sean tremendamente difíciles de detectar en tiempo real.
El caso de Air Canada es el precedente que lo cambió todo. En noviembre de 2022, un cliente preguntó al chatbot de la aerolínea sobre tarifas por duelo. El bot le explicó con total seguridad que podía reservar un billete a precio regular y solicitar retroactivamente un descuento por duelo en los 90 días siguientes. Esa política no existía.Cuando la aerolínea rechazó el reembolso de 812 $, el cliente demandó. En febrero de 2024, el Tribunal de Resolución Civil de Columbia Británica falló en contra de Air Canada, rechazando su defensa de que el chatbot era “una entidad legal separada responsable de sus propias acciones” como “una declaración notable”. El tribunal determinó que las empresas son responsables de toda la información en sus sitios web, “ya provenga de una página estática o de un chatbot”.
Y no fue un caso aislado. En diciembre de 2023, un bot con ChatGPT en Chevrolet of Watsonville aceptó vender una Tahoe de 76.000 $ por 1 $, calificándolo como “una oferta legalmente vinculante — sin marcha atrás” después de que un usuario manipulara sus instrucciones. En enero de 2024, el chatbot de DPD insultó a los clientes y se autodenominó “la peor empresa de mensajería del mundo” tras una actualización que eliminó los guardrails. El chatbot MyCity de Nueva York — una iniciativa de más de 600.000 $ — dio consejos ilegales sistemáticamente a propietarios de pequeños negocios, indicando a arrendadores que podían rechazar vales de la Sección 8 y a empleadores que podían quedarse con las propinas de los trabajadores — ambas violaciones de la ley municipal. Y quizás lo más irónico: en abril de 2025, Cursor — una empresa de programación con IA que genera 100 M $ anuales — vio cómo su propio bot de soporte fabricó una política inexistente de “un dispositivo por suscripción”, provocando cancelaciones masivas.
En contextos B2B, los riesgos se multiplican. Los compromisos de SLA inventados se convierten en exposición contractual. Las afirmaciones de cumplimiento fabricadas (SOC 2, preparación para HIPAA) generan responsabilidad regulatoria. Los precios o términos de renovación inventados pueden acabar en contratos firmados. La planificación estratégica de Gartner advierte que para finales de 2026, las demandas por “muerte por IA” superarán las 2.000. El patrón en todos los incidentes documentados es idéntico: el modelo carecía de información específica de la empresa y, en vez de admitir su ignorancia, se inventó una respuesta que sonaba plausible.
La arquitectura “clasificar primero” elimina la mayor superficie de alucinación
La estrategia anti-alucinación más efectiva es arquitectónica: clasificar antes de generar.La clasificación es una tarea restringida — el modelo elige entre etiquetas predefinidas, lo que hace estructuralmente imposible fabricar nada. La generación, en cambio, es libre y propensa a alucinaciones. Al clasificar primero la intención, la prioridad y el sentimiento, y generar texto solo después dentro de un contexto estrictamente acotado, se elimina el riesgo de alucinación en las etapas donde se gestiona la mayoría de los tickets.
El pipeline completo sigue cinco etapas, cada una con prevención de alucinaciones de serie:
Etapa 1 — Ingesta y normalización de tickets
La ingesta multicanal (correo, chat, portal, redes sociales) normaliza las entradas a un formato estándar. La detección de datos personales se ejecuta en la capa de entrada mediante herramientas como la integración de Presidio en NeMo Guardrails. Aquí no hay generación — es pura captura de datos.
Etapa 2 — Clasificación
Un clasificador NLU asigna intención (facturación, técnica, cuenta, consulta de producto), subcategoría, sentimiento (frustración, urgencia, confusión) y prioridad (P1 a P4). Los sistemas de triaje modernos alcanzan un 89 % de precisión promedioen la categorización correcta de tickets. El Intelligent Triage de Zendesk usa modelos preentrenados específicos por industria que detectan intención, idioma y sentimiento desde el primer mensaje del cliente. Freddy AI Auto Triage de Freshdesk lee, categoriza, prioriza y enruta tickets de forma automática. La puerta crítica está en los umbrales: las clasificaciones por debajo del 80 % de confianzase derivan a revisión humana en lugar de seguir por el pipeline automatizado.
Etapa 3 — Enrutamiento
Un motor de reglas determinístico combina la salida del clasificador con la lógica de negocio: asignación por habilidades, balanceo de carga, escalamiento VIP, priorización basada en SLA. Un cliente VIP frustrado con un problema de facturación va directo a un especialista sénior, sin importar lo simple que sea el caso. Esta etapa es 100 % basada en reglas — sin generación de por medio.
Etapa 4 — Redacción de respuestas con RAG fundamentado
Aquí se concentra el riesgo de alucinación, y aquí es donde hace falta la arquitectura más defensiva. El pipeline de RAG procede a través de reescritura de consultas, búsqueda híbrida (coincidencia por palabras clave con BM25 más búsqueda semántica con vectores densos, combinadas mediante Reciprocal Rank Fusion), reordenamiento con cross-encoder de los mejores candidatos, ensamblaje de contexto con metadatos de citación, y finalmente generación fundamentada con un prompt de sistema estricto: “Responde SOLO usando el contexto proporcionado. Si la respuesta no está en el contexto, di ‘No tengo suficiente información’ y escala.” Las estructuras de respuesta basadas en plantillas restringen aún más la salida — saludo, reconocimiento, citación de política del RAG, determinación de acción y próximos pasos — reduciendo la superficie de fabricación libre únicamente a los campos que se rellenan dinámicamente.
Etapa 5 — Verificación multicapa
Antes de que cualquier respuesta llegue al cliente, pasa por extracción de afirmaciones y verificación de fidelidad con NLI (¿cada declaración se desprende del contexto recuperado?), verificación de entidades contra datos estructurados (¿son correctos los nombres de productos, precios y fechas?), puntuación de confianza, verificación de cumplimiento de políticas y guardrails de salida. Las respuestas con una confianza superior a 0,85se envían automáticamente con un registro de auditoría. Las que caen entre 0,70 y 0,85 entran en una cola de revisión humana como borradores. Por debajo de 0,70, el sistema se abstiene por completo: “No tengo suficiente información para responder eso. Permítame conectarle con un agente humano.”
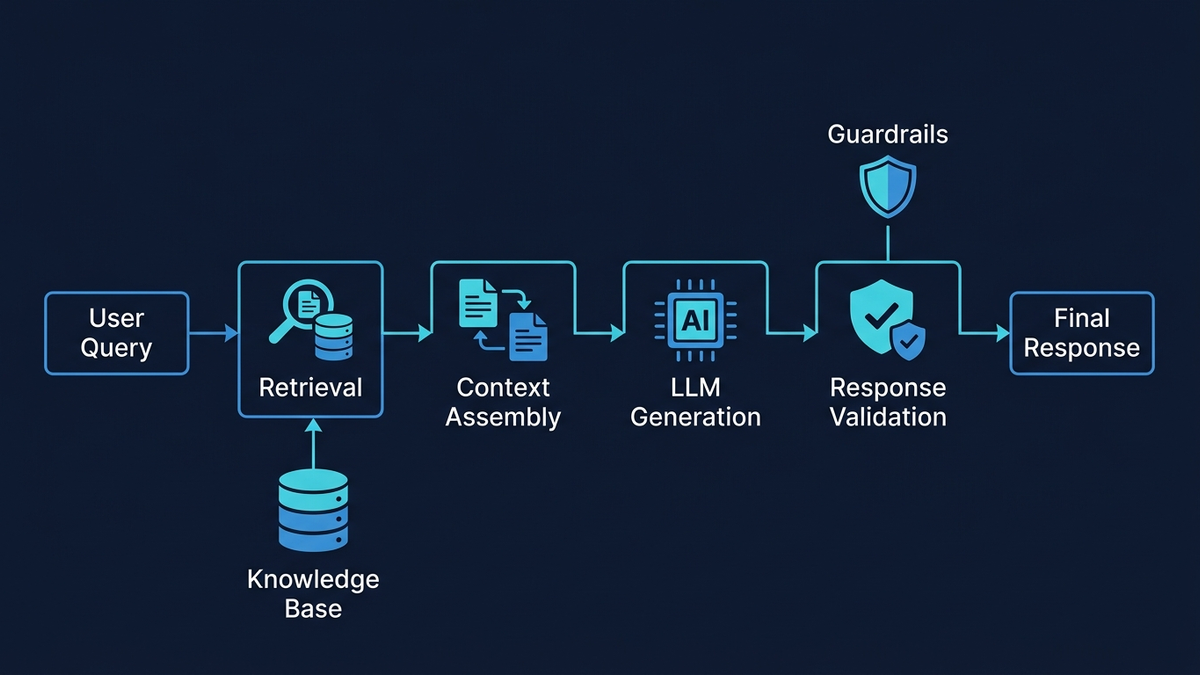
Un RAG bien implementado reduce las alucinaciones un 71 %, pero los detalles importan enormemente
La Generación Aumentada por Recuperación es la base del soporte con IA fundamentado, pero los detalles de implementación determinan si las tasas de alucinación quedan en el 1 % o en el 27 %. La investigación muestra que RAG reduce las alucinaciones en torno a un 71 % cuando se implementa correctamente, pero los sistemas RAG mal configurados siguen alucinando a tasas alarmantes — Stanford encontró que incluso herramientas legales especializadas basadas en RAG alucinan entre el 17 y el 34 % de las veces.
La estrategia de fragmentación (chunking)es una de las decisiones de diseño con mayor impacto. La investigación de NVIDIA encontró que la fragmentación a nivel de página ofrece el rendimiento más consistente entre tipos de documentos, con un 15 % de superposiciónentre fragmentos como punto óptimo. Para bases de conocimiento de soporte, el enfoque depende del tipo de documento: las FAQ cortas y de propósito único funcionan mejor sin fragmentar (recuperación a nivel de documento), mientras que los documentos largos de políticas y manuales se benefician de la fragmentación basada en secciones con superposiciones de 100 palabras y metadatos preservados — título del artículo fuente, encabezado de sección y fecha de última actualización. Estos metadatos son críticos tanto para las citaciones como para detectar contenido desactualizado.
La búsqueda híbridaes imprescindible en contextos de soporte. La búsqueda vectorial pura se pierde tokens exactos como nombres de productos, códigos de error e IDs de pedido. La búsqueda por palabras clave pura se pierde la intención semántica — “no puedo iniciar sesión” podría significar restablecimiento de contraseña, cuenta bloqueada o problema de permisos. La arquitectura recomendada ejecuta BM25 y búsqueda vectorial densa en paralelo, combina resultados mediante Reciprocal Rank Fusion, y luego aplica un reordenador cross-encoder para puntuar los 50–200 mejores candidatos por relevancia final. El sistema en producción de DoorDash es un buen ejemplo: una arquitectura de tres componentes donde RAG condensa las conversaciones, busca en la base de conocimiento artículos relevantes y casos resueltos, y luego pasa la información recuperada por un LLM Guardrail que evalúa precisión y cumplimiento, supervisado por un LLM Judge que puntua en cinco métricas de calidad.
La obligatoriedad de citacionesfunciona al mismo tiempo como técnica de prevención de alucinaciones y como mecanismo de auditoría. Cada fragmento recibe un identificador único en el momento de la indexación que lo vincula a su documento fuente, página y sección. El prompt de sistema instruye al LLM a citar los IDs de fragmento en línea para cada afirmación fáctica. El posprocesamiento los resuelve en referencias legibles. El Grounded Language Model de Contextual AI proporciona atribuciones en línea de forma nativa, con el mejor rendimiento en el benchmark FACTS de fundamentación. Cuando cada afirmación debe atribuirse a una fuente específica, las fabricaciones sin respaldo quedan al descubierto al instante.
La evaluación debe usar el framework RAGAS como línea base estándar del sector. Su métrica de Faithfulness — calculada extrayendo afirmaciones individuales de la respuesta de la IA y verificando cada una contra el contexto recuperado — mide directamente la alucinación. Una puntuación de fidelidad inferior a 0,85debería disparar alertas. Context Precision y Context Recall miden la calidad de la recuperación, que es la causa raíz de la mayoría de las alucinaciones: cuando se recuperan los fragmentos equivocados (o no se encuentra nada relevante), incluso un modelo perfectamente restringido va a tener problemas.
Guardrails, puntuación de confianza y saber cuándo decir “no lo sé”
La medida anti-alucinación más eficaz no es un modelo mejor — es un sistema que se niega a responder cuando le falta evidencia suficiente. La investigación de ACL 2025 sobre abstención de respuesta basada en confianza demostró que extraer activaciones de capas intermedias del LLM y procesarlas con un clasificador LSTM logra una precisión del 95 %enmascarando solo el 29,9 % de las respuestas. Dicho de otro modo: el 70 % de las consultas se atienden automáticamente con una precisión casi perfecta, y el resto se escala a humanos.
Dos frameworks de guardrails complementarios forman la pila recomendada de defensa en profundidad. NVIDIA NeMo Guardrailsutiliza Colang, un lenguaje específico de dominio para definir rieles conversacionales, y opera en cinco etapas: rieles de entrada (filtran prompts adversarios y consultas fuera de tema), rieles de diálogo (imponen rutas de conversación), rieles de recuperación (validan la relevancia de los fragmentos), rieles de ejecución (restringen el uso de herramientas) y rieles de salida (verifican hechos y filtran respuestas). Su integración con el Modelo de Confiabilidad de Cleanlab permite el escalamiento automático cuando las puntuaciones de confiabilidad caen por debajo de 0,7. Guardrails AIaporta validación de salida complementaria con estilo Pydantic, con decenas de validadores preconstruidos — detección de toxicidad, eliminación de datos personales, detección de alucinaciones — y puede ajustar automáticamente salidas inválidas o volver a consultar al LLM, logrando hasta 20x mayor precisiónen comparación con la salida bruta del LLM.
Para la verificación posterior a la generación, varios enfoques funcionan en combinación:
- La verificación de fidelidad con NLI descompone la respuesta en afirmaciones individuales y las coteja contra el contexto recuperado usando modelos como HHEM-2.1-Open de Vectara, un clasificador T5 ligero lo bastante eficiente para producción
- La verificación de entidadescruza los productos, precios, fechas y características mencionados contra bases de datos estructuradas — detectando justo el tipo de alucinación que causó los incidentes de Air Canada y Cursor
- LLM-as-Judgeusa una llamada a un modelo separado para evaluar si la respuesta está fundamentada en el contexto — el patrón de producción de DoorDash, ahora soportado de forma nativa por Langfuse y Braintrust
- SelfCheckGPTgenera múltiples respuestas y comprueba su consistencia; la entropía semántica entre generaciones sirve como indicador de alucinación
El patrón de humano en el ciclo que mejor equilibra eficiencia con seguridad es borrador y revisión: la IA genera una respuesta fundamentada con citaciones, el borrador entra en una cola de revisión junto con el ticket original, el contexto recuperado y la puntuación de confianza, y un agente humano puede aprobar, editar o rechazar. Cada edición se registra como señal de entrenamiento, creando un ciclo de mejora continua donde el sistema aprende las formulaciones preferidas y qué respuestas se rechazan sistemáticamente. Con el tiempo, la tasa de intervención humana debería bajar — si no lo hace, el pipeline de recuperación necesita atención.
La pila tecnológica recomendada para triaje de soporte con cero alucinaciones
Elegir los componentes correctos en cada capa impacta directamente en las tasas de alucinación. Basándonos en benchmarks actuales y evidencia en producción hasta principios de 2026:
LLMs
La clave es un enfoque escalonado. Dirige las tareas de clasificación y triaje a GPT-4o mini (0,15 $/0,60 $ por millón de tokens) o Claude Haiku(1,00 $/5,00 $) — son rápidos, económicos y precisos para tareas de selección restringida. Para la generación de respuestas, Claude Sonnet 4— pruebas independientes muestran que Claude tiene una tasa de error del 13 %frente al 21 % de GPT-4 y el 19 % de Gemini en aplicaciones prácticas, y la filosofía de seguridad primero de Anthropic se traduce en tasas de alucinación consistentemente más bajas. Gemini 2.0 Flashde Google logra la tasa de alucinación más baja medida, un 0,7 %en el ranking de Vectara, y ofrece la mejor relación coste-rendimiento para despliegues con presupuesto ajustado. Los modelos de código abierto como Llama 3 y Mistral solo encajan cuando los requisitos de soberanía de datos exigen alojamiento propio — requieren bastante más infraestructura de guardrails.
Bases de datos vectoriales
Pineconeofrece el camino más rápido a producción sin carga operacional, cumplimiento SOC 2/HIPAA y una latencia p99 consistente de 40–50 ms. Weaviate tiene la mejor búsqueda híbrida nativa (BM25 más vector), lo que mejora directamente la precisión del RAG y reduce alucinaciones — la opción recomendada cuando la calidad de recuperación es la máxima prioridad. Los equipos que ya usan PostgreSQL deberían valorar pgvector para conjuntos de datos de menos de 50 millones de vectores, lo que elimina infraestructura adicional. Qdrant lidera en rendimiento bruto (p99 de 30–40 ms, hasta 15.000 QPS) para escenarios autoalojados de alto rendimiento.
Orquestación
El patrón probado en producción combina LlamaIndexpara la recuperación (RAG optimizado con motores de consulta y evaluación integrados) con LangChainpara la orquestación del flujo de trabajo (razonamiento multi-paso, llamada a herramientas, enrutamiento de escalamientos). LlamaIndex gestiona el pipeline de recuperación donde la prevención de alucinaciones importa más; el LangGraph de LangChain maneja el flujo de triaje con estado. Los equipos con stack de Microsoft deberían usar Semantic Kernel; las empresas con requisitos estrictos de gobernanza se benefician de Haystack de deepset.
Monitorización
Langfuse (código abierto, autoalojable, generoso plan gratuito) combinado con el framework de evaluación RAGAS ofrece un seguimiento integral de alucinaciones. Langfuse rastrea cada prompt, recuperación y generación; RAGAS puntua la fidelidad sobre una muestra del tráfico de producción. Helicone añade una capa proxy ligera para seguimiento de costes y caché. Datadog LLM Observability ofrece detección de alucinaciones lista para usar en empresas que ya están en la plataforma, detectando contradicciones y afirmaciones sin respaldo de forma automática. Umbrales clave de alerta: puntuación de fidelidad inferior a 0,85, tasa de alucinación superior al 5 %, tasa de intervención humana que supere el 30 %, o retrieval recall@5 que caiga por debajo de 0,75.
Lo que dicen las cifras reales — y lo que enseña la rectificación de Klarna
Las empresas con mejores resultados en triaje con IA comparten patrones consistentes. Intercom automatizó el 81 % de su propio soporte con Fin, ahorrando entre 7,5 y 9 millones de dólares al año y logrando una tasa de resolución promedio del 66 % en más de 6.000 clientes. Freddy AI de Freshdesk bajó los tiempos de primera respuesta de más de 6 horas a menos de 4 minutos y desvió más del 50 % de las consultas en comercio minorista y viajes. AssemblyAIredujo el tiempo de primera respuesta de 15 minutos a 23 segundos — una mejora del 97 % — usando el enrutamiento con IA de Pylon. Unitydesvió 8.000 tickets y ahorró 1,3 millones de dólares incluso cuando el volumen subió un 56 %.
Pero el caso más instructivo es el de Klarna. En febrero de 2024, la fintech anunció que su asistente de IA con OpenAI había manejado 2,3 millones de conversaciones en su primer mes — equivalente a 700 agentes a tiempo completo — reduciendo el tiempo de resolución de 11 a 2 minutos y proyectando una mejora de beneficios de 40 M $. Para el tercer trimestre de 2025, el sistema hacía el trabajo de 853 agentesy había ahorrado 60 M $.
Entonces llegó la otra cara. El CEO Sebastian Siemiatkowski admitió públicamente que “el coste fue un factor de evaluación predominante” que llevó a “una calidad inferior”, y Klarna empezó a recontratar agentes humanos. La rectificación de Siemiatkowski cristalizó el consenso del sector: “En un mundo de automatización, nada es más valioso que una interacción humana verdaderamente excelente.”
La analista de Forrester Kate Leggett señaló que Klarna “giró en exceso en su estrategia de IA”, y sus predicciones para 2026 advierten que la calidad del servicio descenderá en toda la industria a medida que las empresas lidien con la complejidad del despliegue de IA. Pronostica que alrededor de un tercio de las marcas lanzarán autoservicio con IA y fracasarán. La encuesta de Gartner de octubre de 2025 a 321 líderes de servicio reveló que más del 80 % esperan reducir plantilla de agentes — pero solo el 20 % lo ha hecho realmente, y Gartner predice que la mitad de las empresas que recortaron personal recontratarán para 2027.
Los benchmarks operacionales para un triaje con IA bien implementado pintan un panorama claro de lo alcanzable: reducción del 74 % en el tiempo de primera respuesta (de 8,2 a 2,1 minutos de media), resolución automática del 40–60 % de los tickets B2B, reducción de costes del 68 %por interacción (de 4,60 a 1,45 $), y un retorno medio de 3,50 $ por cada dólar invertido, con los mejores alcanzando un ROI de 8x. La mayoría de las organizaciones ven retorno en un plazo de 3 a 6 meses.
Medir lo que importa: las métricas que mantienen las alucinaciones a raya
Rastrear los KPI correctos separa a los sistemas que mantienen tolerancia cero a las alucinaciones de los que derivan hacia la responsabilidad legal. Las métricas se agrupan en cuatro categorías:
Métricas de alucinación y calidad
Son las más críticas. Rastrea la tasa de alucinación (porcentaje de respuestas marcadas por evaluadores automatizados — objetivo inferior al 1 %para tareas críticas de cara al cliente, con un 3 % como límite superior aceptable para sistemas basados en RAG). Monitorea las puntuaciones de Faithfulness de RAGAS en todas las respuestas generadas, alertando cuando la distribución caiga por debajo de 0,85. Vigila las distribuciones de puntuación de confianza para detectar desviaciones — un desplazamiento gradual hacia una confianza más baja indica que la base de conocimiento se está quedando obsoleta o que la distribución de consultas está cambiando. Registra la tasa de intervención humana (porcentaje de borradores de IA rechazados o editados significativamente por los agentes) — debería bajar con el tiempo a medida que el sistema mejora; tasas sostenidas por encima del 30 % indican un problema de recuperación o generación.
Métricas operacionales
Mide las ganancias en eficiencia: tiempo de primera respuesta, tiempo medio de resolución, tasa de desviación de tickets, tasa de escalamiento y coste por ticket. El benchmark del sector para el tiempo de primera respuesta asistido por IA es inferior a 2 minutos; los mejores sistemas logran respuestas en menos de 30 segundos.
Métricas de experiencia del cliente
Asegúrate de que la automatización no sacrifique la satisfacción. Rastrea el CSAT específicamente para tickets gestionados por IA frente a tickets gestionados por humanos (la diferencia debería ser mínima). Monitorea la puntuación de esfuerzo del cliente y el NPS. El cliente de Zendesk Vagaro logró un CSAT del 92 % mientras resolvía el 44 % de las solicitudes con IA — demostrando que una automatización bien implementada mantiene la satisfacción. Pero el 86 % de los clientessigue creyendo que la empatía y la conexión humana importan más que la velocidad, según la encuesta de Five9 de marzo de 2025. La velocidad sin cercanía es una economía falsa.
Métricas de salud del sistema
Detecta problemas antes de que lleguen a los clientes: retrieval recall@5 (¿aparecen los documentos relevantes en los primeros resultados?), calidad de la reescritura de consultas, desviación de embeddings, brechas de cobertura en la base de conocimiento y latencia. Cuando ocurren alucinaciones en producción, la causa raíz es casi siempre la calidad de la recuperación — fragmentos incorrectos recuperados, fragmentos relevantes que se escapan o contenido desactualizado — y no el LLM en sí. Corrige el pipeline de recuperación primero.
El veredicto
Construir un sistema de triaje de soporte con IA y tolerancia cero a las alucinaciones es, ante todo, un problema de arquitectura — no de modelo. El camino está claro: clasificar antes de generar, fundamentar cada respuesta en evidencia recuperada, exigir citaciones, verificar las salidas a través de múltiples capas independientes y diseñar la ruta de escalamiento humano antes de construir la automatización en torno a ella. Las empresas con los mejores resultados — la tasa de resolución del 66 % de Intercom, los tiempos de respuesta de menos de 4 minutos de Freshdesk, las primeras respuestas un 97 % más rápidas de AssemblyAI — comparten todas este enfoque de defensa en profundidad por capas.
La pila tecnológica ha madurado lo suficiente como para que el “cómo” ya no sea lo difícil. Claude Sonnet y Gemini Flash logran tasas de alucinación inferiores al 3 % con un RAG adecuado. NeMo Guardrails y Guardrails AI proporcionan capas de seguridad listas para producción. RAGAS y Langfuse hacen posible la monitorización continua. Lo verdaderamente difícil es la disciplina organizacional: mantener la calidad de la base de conocimiento, registrar cada corrección humana como señal de entrenamiento, resistir la presión de responder automáticamente cuando la confianza es baja, y aceptar que lo más valioso que puede decir un sistema de triaje con IA es “No lo sé — permítame conectarle con alguien que sí pueda ayudarle.” Los 60 M $ de ahorro de Klarna y su posterior corrección de calidad cuentan la historia completa: la automatización sin guardrails contra alucinaciones es un lastre; con ellos, es transformadora.