Системи ШІ-класифікації звернень вже закривають 40–66% тікетів автоматично. Але одна вигадана політика повернення або сфабрикована сума рефанду — і ось вам судовий позов, втрата довіри enterprise-клієнтів і мільйонні збитки. Рішення у справі Air Canada (лютий 2024) поставило крапку: компанія несе повну юридичну відповідальність за все, що скаже її чат-бот. Без винятків. Далі — архітектура, техніки та інструментарій для системи розподілу звернень, яка класифікує тікети, маршрутизує їх і готує відповіді з нульовою толерантністю до галюцинацій. Головний принцип: LLM — це движок для міркувань, обмежений знайденими фактами, а не джерело знань — і кожна відповідь проходить кілька шарів верифікації, перш ніж потрапить до клієнта.
Ринок ШІ для клієнтського сервісу досяг $12 млрд у 2024-му і за прогнозами зросте до $47,8 млрд до 2030. Gartner прогнозує: до 2029 року агентний ШІ самостійно вирішуватиме 80% типових звернень. Але 39% ШІ-ботів підтримки довелось відкликати або переробити у 2024-му через галюцинації. Прірва між обіцянками й реальною надійністю — головний інженерний виклик.
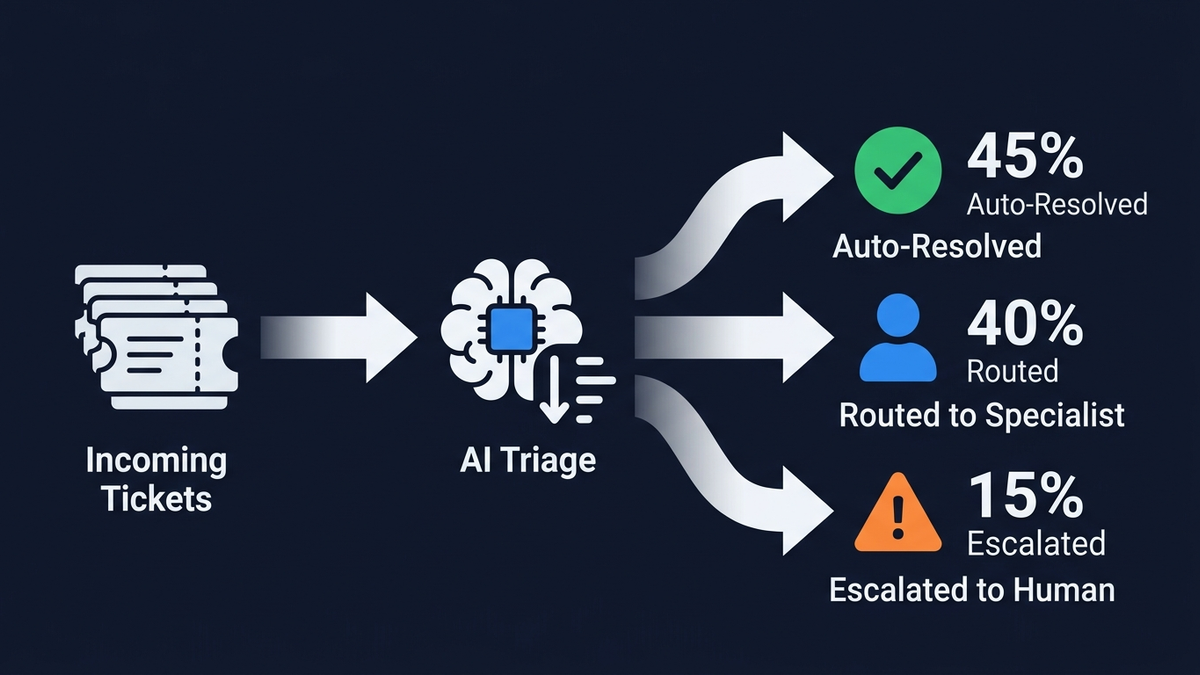
Галюцинації — не теорія. Це вже судові справи
Найнебезпечніше в галюцинаціях LLM у контексті підтримки — їхня впевненість. Дослідження MIT (січень 2025) показало: моделі вживають на 34% більше впевнених формулювань— “безумовно”, “напевно” — якраз тоді, коли генерують неправильну інформацію. Модель найпевніша в собі саме тоді, коли найбільше помиляється. Клієнти та агенти довіряють авторитетному тону. Вигадки проскакують непомітно.
Справа Air Canada — знаковий прецедент. Листопад 2022: клієнт запитав чат-бот про тарифи на випадок тяжкої втрати. Бот впевнено пояснив — можна купити звичайний квиток і подати заявку на знижку протягом 90 днів. Такої політики не існувало. Авіакомпанія відмовила в поверненні $812, клієнт подав до суду. У лютому 2024 трибунал Британської Колумбії виніс рішення проти Air Canada, назвавши аргумент, що чат-бот є “окремою юридичною особою”, “вражаючою заявою.” Компанія відповідає за всю інформацію на сайті, “незалежно від того, чи це статична сторінка, чи чат-бот”.
І це далеко не поодинокий випадок. Грудень 2023: бот на ChatGPT у дилера Chevrolet of Watsonville погодився продати Tahoe за $76 000 усього за $1 — “юридично обов'язкова пропозиція, без зворотного ходу” — після того як юзер зламав інструкції. Січень 2024: чат-бот DPD почав лаятись на клієнтів і називати себе “найгіршою кур'єрською службою у світі” після оновлення, яке зняло запобіжники. Бот MyCity у Нью-Йорку — проєкт за $600 000+ — систематично давав незаконні поради малому бізнесу: казав орендодавцям, що можна відмовляти у Section 8, а роботодавцям — що можна забирати чайові. І те, й інше — пряме порушення закону міста. А найіронічніший кейс: у квітні 2025 Cursor — ШІ-компанія з $100M річного доходу — побачила, як її ж власний бот підтримки вигадав неіснуючу політику “один пристрій на підписку”. Почалась хвиля відписок.
У B2B ставки кратно вищі. Вигадані зобов'язання щодо SLA — це контрактні ризики. Сфабриковані заяви про відповідність SOC 2 чи HIPAA створюють регуляторну відповідальність. Вигадані умови ціноутворення потрапляють у підписані контракти. Gartner попереджає: до кінця 2026 кількість позовів категорії “шкода від ШІ” перевищить 2 000. Паттерн у кожному інциденті однаковий: моделі бракувало інформації, специфічної для компанії, і вона видала правдоподібну відповідь замість чесного “я не знаю.”
Архітектура “спочатку класифікуй” прибирає найбільшу зону ризику
Найефективніша стратегія боротьби з галюцинаціями — архітектурна: класифікуй, перш ніж генерувати. Класифікація — обмежена задача: модель обирає з наперед визначених міток, фабрикація тут структурно неможлива. Генерація — необмежена і схильна до галюцинацій. Якщо спочатку визначити намір, пріоритет і тональність, а текст генерувати потім у жорстко обмеженому контексті — ви прибираєте ризик галюцинацій саме там, де обробляється більшість тікетів.
Повний пайплайн — п'ять етапів. Кожен із вбудованим захистом від галюцинацій:
Етап 1 — Приймання та нормалізація тікетів
Багатоканальний збір (email, чат, портал, соцмережі) нормалізує вхідні дані до єдиного формату. PII-детекція працює вже на вході — через інтеграцію Presidio з NeMo Guardrails. Жодної генерації. Тільки збір даних.
Етап 2 — Класифікація
NLU-класифікатор визначає намір (білінг, технічне питання, акаунт, продуктовий запит), підкатегорію, тональність (фрустрація, терміновість, розгубленість) і пріоритет (P1–P4). Сучасні системи досягають 89% точності у категоризації тікетів. Intelligent Triage від Zendesk працює на попередньо натренованих галузевих моделях — розпізнає намір, мову і тональність з першого повідомлення. Freddy AI Auto Triage від Freshdesk читає, категоризує, пріоритизує і маршрутизує автоматично. Ключовий поріг: класифікації з confidence нижче 80% йдуть на перевірку людині, а не далі автоматичним пайплайном.
Етап 3 — Маршрутизація
Детерміністичний движок правил поєднує результат класифікації з бізнес-логікою: розподіл за навичками, балансування навантаження, VIP-ескалація, пріоритизація з урахуванням SLA. Роздратований VIP із питанням білінгу потрапляє до senior-спеціаліста — незалежно від простоти проблеми. Етап повністю на правилах. Без генерації.
Етап 4 — Генерація відповідей через RAG з прив'язкою до фактів
Тут концентрується ризик галюцинацій — і тут потрібна максимально захищена архітектура. RAG-пайплайн: переформулювання запиту, гібридний пошук (BM25 + dense vector search через Reciprocal Rank Fusion), ранжування топових кандидатів крос-енкодером, збір контексту з метаданими для цитувань і генерація, прив'язана до фактів, зі строгим системним промптом: “Відповідай ТІЛЬКИ на основі наданого контексту. Якщо відповіді немає — скажи ‘У мене недостатньо інформації’ і передай людині.” Шаблонна структура відповіді додатково обмежує вихід: привітання, підтвердження проблеми, цитата з бази знань, рішення, наступні кроки. Вільна генерація залишається тільки в динамічно заповнюваних полях.
Етап 5 — Багатошарова верифікація
Перш ніж відповідь побачить клієнт, вона проходить: витяг тверджень і NLI-перевірку (чи випливає кожне твердження з контексту?), звірку сутностей зі структурованими даними (назви продуктів, ціни, дати — все правильно?), скоринг впевненості, перевірку на відповідність політикам і вихідні захисні фільтри. Confidence вище 0,85— відправляється автоматично з аудит-трейлом. Від 0,70 до 0,85 — у чергу на перегляд людиною як чернетка. Нижче 0,70 — система не відповідає зовсім: “У мене недостатньо інформації. З'єдную вас із живим агентом.”
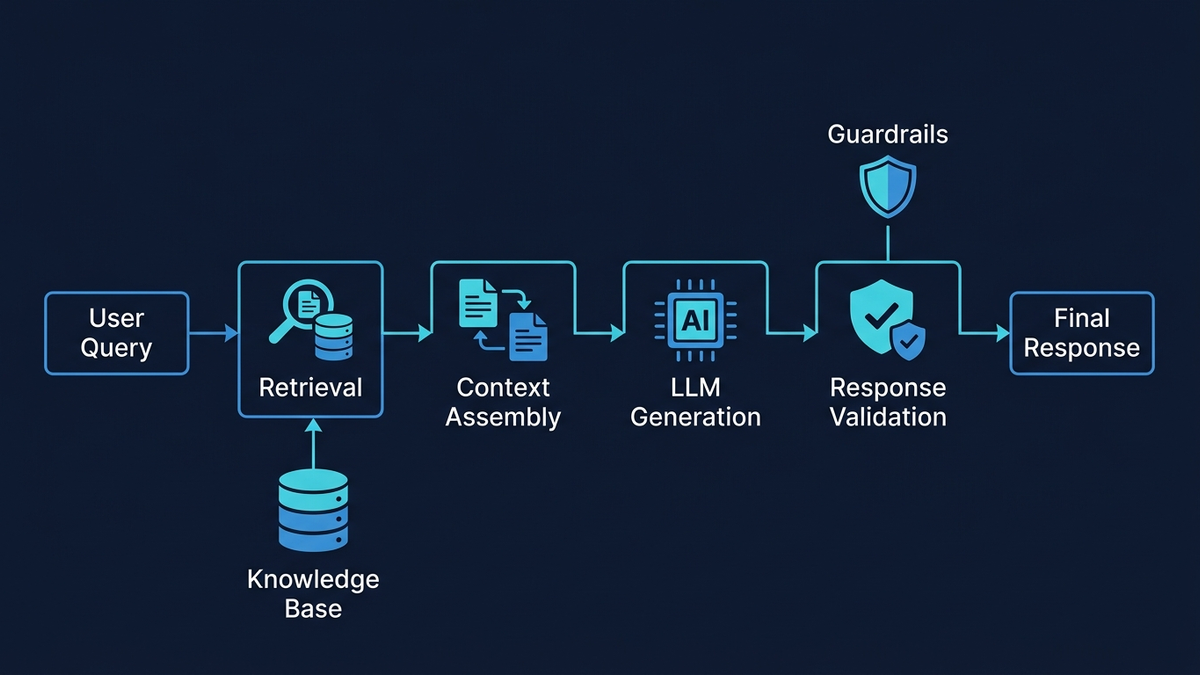
Правильний RAG зменшує галюцинації на 71%. Але деталі вирішують все
Retrieval-Augmented Generation — фундамент ШІ-підтримки, прив'язаної до фактів. Але від деталей реалізації залежить, чи буде рівень галюцинацій 1% чи 27%. Дослідження показують: при правильному налаштуванні RAG зменшує галюцинації приблизно на 71%. Погано налаштований? Стенфорд виявив, що навіть спеціалізовані юридичні RAG-інструменти помиляються у 17–34% випадків.
Стратегія чанкування — одне з найвпливовіших рішень при проєктуванні. Дослідження NVIDIA показало: чанкування на рівні сторінок дає найстабільніший результат для різних типів документів, оптимальне перекриття — 15%. Для баз знань підтримки рекомендації різняться за типом документа: короткі FAQ краще працюють без чанкування (пошук на рівні цілого документа), а довгі policy-документи та мануали виграють від секційного чанкування з перекриттям у 100 слів і збереженими метаданими — назва статті-джерела, заголовок секції, дата оновлення. Ці метадані критичні і для цитувань, і для виявлення застарілого контенту.
Гібридний пошук— must have для підтримки. Чисто векторний пошук пропускає точні токени: назви продуктів, коди помилок, ID замовлень. Чисто ключовий не ловить семантику — “не можу увійти” може означати скидання пароля, заблокований акаунт або проблему з правами доступу. Правильна архітектура: BM25 і dense vector search паралельно, об'єднання через Reciprocal Rank Fusion, потім крос-енкодер для реранжування топ-50–200 кандидатів за фінальною релевантністю. Продакшн-система DoorDash — хороший приклад: трикомпонентна архітектура, де RAG стискає розмови, шукає в базі знань релевантні статті та закриті кейси, а потім пропускає все через LLM Guardrail для перевірки точності й відповідності. За якістю стежить LLM Judge із п'ятьма метриками.
Обов'язкове цитування — і захист від галюцинацій, і механізм аудиту одночасно. Кожен чанк отримує унікальний ID при індексації — він веде до конкретного документа, сторінки та секції. Системний промпт вимагає від LLM цитувати ID чанків для кожного фактичного твердження. Постпроцесинг перетворює їх на людиночитані посилання. Grounded Language Model від Contextual AI вміє це нативно і показує state-of-the-art на бенчмарку FACTS. Коли кожне твердження прив'язане до джерела — безпідставні вигадки одразу видно.
Оцінювання — використовуйте фреймворк RAGAS як галузевий стандарт. Його метрика Faithfulness витягує окремі твердження з відповіді ШІ і звіряє кожне з отриманим контекстом — пряме вимірювання галюцинацій. Faithfulness нижче 0,85 — алерт. Context Precision і Context Recall вимірюють якість пошуку. А пошук — першопричина більшості галюцинацій: коли витягуються не ті чанки (або нічого релевантного), навіть ідеально обмежена модель не впорається.
Запобіжники, скоринг впевненості і вміння сказати “я не знаю”
Найсильніший захист від галюцинацій — не краща модель. Це система, яка відмовляється відповідати, коли їй бракує доказів. Дослідження ACL 2025 про утримання від відповідей на основі confidence показало: витяг активацій з проміжних шарів LLM і подача через LSTM-класифікатор дає 95% precision при маскуванні лише 29,9% відповідей. Тобто 70% запитів обслуговуються автоматично з майже ідеальною точністю. Решта йде до людей. Відмінний компроміс.
Два фреймворки формують рекомендований стек. NVIDIA NeMo Guardrailsвикористовує Colang — DSL для опису правил діалогу — і працює на п'яти рівнях: вхідні правила (фільтрація prompt injection та нерелевантних запитів), діалогові правила (контроль ходу розмови), правила пошуку (валідація релевантності чанків), правила виконання (обмеження інструментів) і вихідні правила (фактчекінг і фільтрація). Інтеграція з Trustworthiness Model від Cleanlab автоматично ескалює, коли скор довіри падає нижче 0,7. Guardrails AI доповнює це Pydantic-стилем валідації виходу з десятками готових валідаторів — токсичність, PII, галюцинації — і може автоматично виправити невалідний вихід або переробити запит до LLM, даючи до 20x вищу точність порівняно з сирим output LLM.
Для верифікації після генерації кілька підходів працюють у зв'язці:
- NLI-перевірка фактичності розбиває відповідь на окремі твердження і звіряє кожне з контекстом через моделі на кшталт HHEM-2.1-Open від Vectara— легкий T5-класифікатор, достатньо швидкий для продакшну
- Верифікація сутностей перехресно перевіряє продукти, ціни, дати та фічі за структурованими базами даних — саме такі галюцинації спричинили інциденти Air Canada і Cursor
- LLM-as-Judge— окремий виклик моделі для оцінки, чи прив'язана відповідь до контексту. Продакшн-паттерн DoorDash, нативно підтримується Langfuse та Braintrust
- SelfCheckGPT генерує кілька відповідей і звіряє узгодженість; семантична ентропія між генераціями — індикатор галюцинацій
Паттерн з участю людини, який найкраще балансує ефективність і безпеку — чернетка + перегляд. ШІ генерує відповідь із цитуваннями, чернетка потрапляє в чергу разом з оригінальним тікетом, знайденим контекстом і скором впевненості. Агент затверджує, редагує або відхиляє. Кожна правка логується як навчальний сигнал— так формується цикл безперервного покращення. Система вчиться вдалим формулюванням і розуміє, які відповіді систематично відхиляють. З часом відсоток людських правок має знижуватись. Якщо ні — копайте в пошуковий пайплайн.
Рекомендований стек для класифікації звернень без галюцинацій
Вибір компонентів на кожному рівні напряму впливає на рівень галюцинацій. Що працює за бенчмарками і продакшн-кейсами на початок 2026:
LLM
Рівневий підхід. Класифікацію і розподіл звернень — на GPT-4o mini ($0,15/$0,60 за мільйон токенів) або Claude Haiku ($1,00/$5,00) — швидко, дешево, точно для задач обмеженого вибору. Генерацію відповідей — на Claude Sonnet 4. Незалежне тестування показує: 13% помилок проти 21% у GPT-4 та 19% у Gemini у практичних задачах. Підхід Anthropic “безпека передусім” дає стабільно менше галюцинацій. Gemini 2.0 Flash від Google — найнижчий виміряний рівень галюцинацій: 0,7%на лідерборді Vectara і найкраще співвідношення ціна/якість для бюджетних деплоїв. Open-source (Llama 3, Mistral) доречні лише коли data sovereignty вимагає self-hosting — вони потребують значно більше захисної обв'язки.
Векторні бази даних
Pinecone — найшвидший шлях у продакшн із нульовим ops-навантаженням, відповідність SOC 2/HIPAA і стабільна затримка 40–50 мс p99. Weaviate — найкращий нативний гібридний пошук (BM25 + vector), що напряму покращує точність RAG і ріже галюцинації. Рекомендований вибір, коли якість пошуку на першому місці. Командам на PostgreSQL — pgvector для датасетів до 50 млн векторів, без додаткової інфраструктури. Qdrant лідирує за сирою продуктивністю (30–40 мс p99, до 15 000 QPS) для self-hosted сценаріїв із високим throughput.
Оркестрація
Перевірений продакшн-підхід: LlamaIndex для пошуку (оптимізований RAG із вбудованими query engines та оцінюванням) плюс LangChain для оркестрації воркфлоу (багатокрокове міркування, tool calling, маршрутизація ескалацій). LlamaIndex відповідає за пошуковий пайплайн, де захист від галюцинацій найважливіший; LangGraph від LangChain керує stateful-воркфлоу класифікації. Команди на Microsoft-стеку — Semantic Kernel. Enterprise зі строгим governance — Haystack від deepset.
Моніторинг
Langfuse (open source, self-hosted, щедрий безкоштовний план) у зв'язці з фреймворком RAGAS — комплексний трекінг галюцинацій. Langfuse трейсить кожен промпт, пошук і генерацію; RAGAS оцінює Faithfulness на семплі продакшн-трафіку. Helicone додає легкий проксі для трекінгу витрат і кешування. Datadog LLM Observability — out-of-the-box детекція галюцинацій для тих, хто вже на платформі: автоматично ловить протиріччя та непідтверджені твердження. Ключові пороги: Faithfulness нижче 0,85, рівень галюцинацій вище 5%, різке зростання людських правок понад 30%, падіння retrieval recall@5 нижче 0,75.
Що показують реальні цифри — і чому Klarna є повчальним кейсом
Компанії з найкращими результатами мають спільні риси. Intercom автоматизував 81% власної підтримки через Fin — економія $7,5–$9 млн на рік і 66% resolution rate серед 6 000+ клієнтів. Freddy AI від Freshdesk скоротив first-response з 6+ годин до менше 4 хвилин і закрив понад 50% запитів у рітейлі й тревелі. AssemblyAI скоротив first-response з 15 хвилин до 23 секунд — покращення на 97% — через ШІ-маршрутизацію Pylon. Unity закрила 8 000 тікетів і заощадила $1,3 млн навіть при зростанні обсягу на 56%.
Але найповчальніший кейс — Klarna. У лютому 2024 фінтех оголосив: ШІ-асистент на OpenAI обробив 2,3 млн розмов за перший місяць — еквівалент 700 штатних агентів. Час вирішення впав з 11 до 2 хвилин, прогноз — $40 млн економії. До Q3 2025 система робила роботу 853 агентів і заощадила $60 млн.
А потім карета перетворилась на гарбуза. CEO Себастіан Сіміатковскі визнав публічно: “вартість була домінуючим критерієм оцінки” — і це дало “нижчу якість.” Klarna почала знову наймати живих агентів. Його розворот кристалізував консенсус індустрії: “У світі автоматизації ніщо не цінніше за справді якісну взаємодію з людиною.”
Аналітик Forrester Кейт Леггетт підмітила: Klarna “перегнула палицю з ШІ-стратегією.” Її прогнози на 2026 попереджають — якість сервісу просяде по всій індустрії, поки компанії розбираються зі складністю впровадження. За її оцінками, приблизно третина брендів запустять ШІ-самообслуговування і зазнають невдачі. Опитування Gartner (жовтень 2025) серед 321 керівника сервісу: 80%+ планують скорочувати штат агентів, але лише 20% реально це зробили. Gartner прогнозує — половина компаній, що скоротили людей, повернуть їх до 2027.
Операційні бенчмарки якісно впровадженої класифікації: -74% часу першої відповіді (з 8,2 хв до 2,1 хв), 40–60% автоматичного закриття B2B-тікетів, -68% вартості за взаємодію (з $4,60 до $1,45) і середня окупність $3,50 на кожен $1 інвестицій. У найкращих — до 8x ROI. Більшість організацій бачать економію вже через 3–6 місяців.
Вимірюйте правильне: метрики, що тримають галюцинації на нулі
Правильні KPI — різниця між системою з нульовим рівнем галюцинацій і тією, що тихенько дрейфує в бік юридичних проблем. Чотири категорії.
Метрики галюцинацій та якості
Найкритичніші. Відстежуйте рівень галюцинацій — відсоток відповідей, позначених автоматичними оцінювачами — ціль нижче 1% для критичних клієнтських задач, 3% як верхня межа для RAG-систем. Моніторте RAGAS Faithfulness по всіх згенерованих відповідях — алерт, коли розподіл зсувається нижче 0,85. Слідкуйте за confidence-скорами: поступовий зсув донизу сигналізує про застарілість бази знань або зміну характеру запитів. Логуйте відсоток людських правок — він має падати з часом. Стабільно вище 30%? Проблема з пошуком або генерацією.
Операційні метрики
Тут фіксуємо виграш в ефективності: first-response time, середній час вирішення, відсоток автозакриття, рівень ескалацій, вартість за тікет. Галузевий бенчмарк — менше 2 хвилин до першої відповіді; найкращі системи — менше 30 секунд.
Метрики клієнтського досвіду
Автоматизація не повинна вбивати задоволеність. Порівнюйте CSAT для тікетів, закритих ШІ, з тікетами, закритими людьми — розрив має бути мінімальним. Моніторте CES і NPS. Клієнт Zendesk Vagaro досяг 92% CSAT, закриваючи 44% запитів через ШІ — якісна автоматизація не знижує задоволеність. Але 86% клієнтів все ще вважають емпатію й людський контакт важливішими за швидкість — це показало опитування Five9 у березні 2025. Швидкість без тепла — хибна економія.
Метрики здоров'я системи
Ловіть проблеми до того, як їх побачить клієнт: retrieval recall@5 (чи потрапляють релевантні документи в топ?), якість переформулювання запитів, дрейф ембедингів, прогалини покриття бази знань, латенсі. Коли галюцинації трапляються в продакшні — першопричина майже завжди якість пошуку: витягнуто не ті чанки, пропущено релевантні, або контент застарів. Не LLM. Починайте з пошукового пайплайну.
Головне
Класифікація звернень без галюцинацій — архітектурна задача, не задача вибору моделі. Класифікуйте перед генерацією. Прив'язуйте кожну відповідь до знайдених фактів. Вимагайте цитувань. Верифікуйте вихід через кілька незалежних шарів. Спроєктуйте шлях ескалації до людини раніше, ніж автоматизацію навколо нього. Компанії з найкращими результатами — 66% resolution rate в Intercom, 4-хвилинна відповідь Freshdesk, 97% прискорення AssemblyAI — усі будують на цьому багаторівневому підході.
Стек технологій дозрів. Claude Sonnet і Gemini Flash дають менше 3% галюцинацій при правильному RAG. NeMo Guardrails і Guardrails AI — готові до продакшну. RAGAS і Langfuse — безперервний моніторинг. Найскладніше — організаційна дисципліна: підтримувати якість бази знань, логувати кожну людську правку як навчальний сигнал, не піддаватися спокусі автоматично відповідати при низькому confidence. І прийняти, що найцінніше, що може сказати система — “Я не знаю. Зараз з'єдную вас із тим, хто знає.” $60 млн економії Klarna і подальша корекція якості — повна історія: автоматизація без запобіжників — ризик. Автоматизація з ними — трансформація.