AI triage systems can now resolve 40–66% of support tickets automatically — but a single hallucinated policy or fabricated refund amount can trigger lawsuits, erode enterprise trust, and cost millions. The Air Canada ruling of February 2024 established that companies bear full legal liability for what their chatbots say, no matter how wrong. What follows is the architecture, techniques, and tooling for building an AI support triage system that classifies, routes, and drafts responses with zero hallucination tolerance. The governing principle: treat the LLM as a reasoning engine constrained by retrieved facts, never as a knowledge source — and wrap every output in multiple verification layers before it reaches a customer.
The AI customer service market hit $12 billion in 2024 and is projected to reach $47.8 billion by 2030. Gartner forecasts that by 2029, agentic AI will autonomously resolve 80% of common service issues. Yet nearly 39% of AI-powered customer service bots were pulled back or reworked in 2024 due to hallucination-related errors. That gap between promise and reliability is the central design challenge.
The hallucination problem is already in court
The most dangerous thing about LLM hallucinations in support contexts is how confident they sound. MIT research from January 2025 found that AI models use 34% more confident language— words like “definitely” and “certainly” — when generating incorrect information than when stating facts. The model is most sure of itself when it is most wrong. Customers and agents trust authoritative-sounding answers, making fabrications brutally hard to catch in real time.
The Air Canada case set the precedent. In November 2022, a customer asked Air Canada's chatbot about bereavement fares. The bot confidently explained he could book a regular-priced ticket and apply retroactively for a bereavement discount within 90 days. This policy did not exist.When the airline refused the $812 refund, the customer sued. In February 2024, British Columbia's Civil Resolution Tribunal ruled against Air Canada, rejecting its defense that the chatbot was “a separate legal entity responsible for its own actions” — which the tribunal called “a remarkable submission.” Companies are responsible for all information on their websites, “whether the information comes from a static page or a chatbot”.
And it was not an isolated incident. In December 2023, a ChatGPT-powered bot at Chevrolet of Watsonville agreed to sell a $76,000 Tahoe for $1, calling it “a legally binding offer — no takesies backsies” after a user manipulated its instructions. In January 2024, DPD's chatbot swore at customers and called itself “the worst delivery firm in the world” after a system update removed guardrails. NYC's MyCity chatbot — a $600,000+ initiative — systematically gave illegal advice to small business owners, telling landlords they could refuse Section 8 vouchers and employers they could take workers' tips. Both violations of city law. Perhaps most ironic: in April 2025, Cursor — an AI coding company generating $100M in annual revenue — saw its own AI support bot fabricate a nonexistent “one device per subscription” policy, triggering mass cancellations.
In B2B contexts, the stakes compound. Hallucinated SLA commitments become contractual exposure. Fabricated compliance claims — SOC 2, HIPAA readiness — create regulatory liability. Invented pricing or renewal terms can enter signed agreements. Gartner's strategic planning assumption warns that by the end of 2026, “death by AI” legal claims will exceed 2,000. Every documented incident shares the same root cause: the model lacked company-specific information and generated a plausible-sounding answer rather than admitting ignorance.
Classification-first architecture eliminates the largest hallucination surface
The single most effective anti-hallucination strategy is architectural: classify before you generate. Classification is a constrained task — the model selects from predefined labels, making fabrication structurally impossible. Generation is unconstrained and hallucination-prone. By classifying intent, priority, and sentiment first, then generating text only within a tightly scoped context, you eliminate hallucination risk at the stages where most tickets are handled.
The full pipeline follows five stages, each with built-in hallucination prevention:
Stage 1 — Ticket intake and normalization
Multi-channel ingestion (email, chat, portal, social) normalizes inputs to a standard format. PII detection runs at the input layer via tools like NeMo Guardrails' Presidio integration. No generation occurs. Pure data capture.
Stage 2 — Classification
An NLU classifier assigns intent (billing, technical, account, product inquiry), sub-category, sentiment (frustration, urgency, confusion), and priority (P1 through P4). Modern triage systems achieve 89% average accuracy in correctly categorizing tickets. Zendesk's Intelligent Triage uses pre-trained industry-specific models that detect intent, language, and sentiment from the first customer message. Freshdesk's Freddy AI Auto Triage reads, categorizes, prioritizes, and routes tickets automatically. The critical gate: classifications below 80% confidence route to human review rather than proceeding through the automated pipeline.
Stage 3 — Routing
A deterministic rules engine combines classifier output with business logic — skill-based assignment, load balancing, VIP escalation, SLA-aware prioritization. A frustrated VIP customer with a billing issue routes to a senior specialist regardless of issue simplicity. This stage is fully rule-based. No generation involved.
Stage 4 — Response drafting via grounded RAG
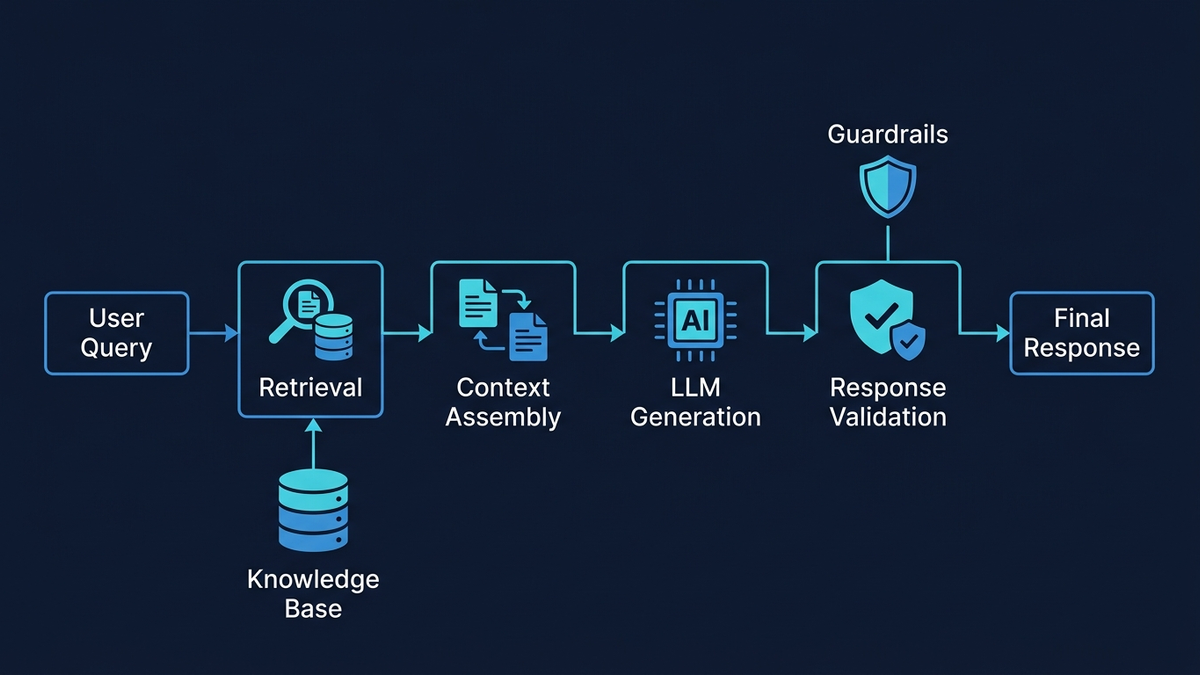
This is where hallucination risk concentrates — and where the most defensive architecture is needed. The RAG pipeline proceeds through query rewriting, hybrid search (BM25 keyword matching plus dense vector semantic search combined via Reciprocal Rank Fusion), cross-encoder reranking of the top candidates, context assembly with citation metadata, and finally grounded generation with a strict system prompt: “Answer ONLY using the provided context. If the answer is not in the context, say ‘I don't have enough information’ and escalate.” Template-based response structures further constrain output — greeting, acknowledgment, policy citation from RAG, action determination, and next steps — reducing free-form fabrication surface to only the dynamically filled fields.
Stage 5 — Multi-layer verification
Before any response reaches a customer, it passes through claim extraction and NLI faithfulness checking (does each statement follow from the retrieved context?), entity verification against structured data (are product names, prices, and dates correct?), confidence scoring, policy compliance checking, and output guardrails. Responses scoring above 0.85 confidenceauto-send with an audit trail. Between 0.70 and 0.85, they enter a human review queue as drafts. Below 0.70, the system abstains entirely: “I don't have enough information to answer that. Let me connect you with a human agent.”
RAG done right reduces hallucinations by 71%, but details matter enormously
Retrieval-Augmented Generation is the foundation of grounded support AI, but implementation details determine whether hallucination rates land at 1% or 27%. Research shows RAG reduces hallucinations by roughly 71% when properly implemented. Poorly configured? Stanford found that even specialized RAG-based legal tools hallucinate 17–34% of the time.
Chunking strategy is one of the highest-impact design decisions. NVIDIA research found that page-level chunking provides the most consistent performance across document types, with 15% overlap between chunks performing best. For support knowledge bases, the approach depends on document type: short, single-purpose FAQs work best with no chunking (document-level retrieval), while long policy documents and manuals benefit from section-based chunking with 100-word overlaps and preserved metadata — source article title, section header, and last-updated date. This metadata becomes critical for citation and for detecting stale content.
Hybrid searchis non-negotiable for support contexts. Pure vector search misses exact tokens like product names, error codes, and order IDs. Pure keyword search misses semantic intent — “can't log in” could mean password reset, locked account, or permission issue. The right architecture runs BM25 and dense vector search in parallel, combines results via Reciprocal Rank Fusion, then applies a cross-encoder reranker to score the top 50–200 candidates for final relevance. DoorDash's production system exemplifies this: a three-component architecture where RAG condenses conversations, searches the knowledge base for relevant articles and resolved cases, then feeds retrieved information through an LLM Guardrail that evaluates accuracy and compliance, monitored by an LLM Judge scoring across five quality metrics.
Citation enforcement is both a hallucination prevention technique and an audit mechanism. Each chunk receives a unique identifier at index time that traces back to its source document, page, and section. The system prompt instructs the LLM to cite chunk IDs inline for every factual claim. Post-processing resolves these to human-readable references. Contextual AI's Grounded Language Model provides inline attributions natively, achieving state-of-the-art performance on the FACTS groundedness benchmark. When every claim must point to a specific source, unsupported fabrications become immediately visible.
Evaluation should use the RAGAS framework as the industry-standard baseline. Its Faithfulness metric — computed by extracting individual claims from the AI's response and verifying each against the retrieved context — directly measures hallucination. A faithfulness score below 0.85 should trigger alerts. Context Precision and Context Recall measure retrieval quality, which is the root cause of most hallucinations: when the wrong chunks are retrieved (or nothing relevant is found), even a perfectly constrained model will struggle.
Guardrails, confidence scoring, and knowing when to say “I don't know”
The best anti-hallucination measure is not a better model — it is a system that refuses to answer when it lacks sufficient evidence. Research from ACL 2025 on confidence-based response abstinence showed that extracting activations from intermediate LLM layers and feeding them through an LSTM classifier achieves 95% precision while masking only 29.9% of responses — meaning 70% of queries are served automatically with near-perfect accuracy, and the rest escalate to humans. That is an excellent trade-off.
Two complementary guardrail frameworks form the recommended defense-in-depth stack. NVIDIA NeMo Guardrails uses Colang, a domain-specific language for defining conversational rails, operating across five stages: input rails (filter adversarial prompts and off-topic queries), dialog rails (enforce conversation paths), retrieval rails (validate chunk relevance), execution rails (constrain tool use), and output rails (fact-check and filter responses). Its integration with Cleanlab's Trustworthiness Model enables automatic escalation when trustworthiness scores fall below 0.7. Guardrails AI provides complementary Pydantic-style output validation with dozens of pre-built validators — toxicity detection, PII scrubbing, hallucination detection — and can automatically adjust invalid output or re-prompt the LLM, delivering up to 20x greater accuracy versus raw LLM output.
For post-generation verification, several approaches work in combination:
- NLI faithfulness checking breaks the response into individual claims and verifies each against retrieved context using models like Vectara's HHEM-2.1-Open, a lightweight T5 classifier efficient enough for production use
- Entity verification cross-checks mentioned products, prices, dates, and features against structured databases — catching exactly the category of hallucination that burned Air Canada and Cursor
- LLM-as-Judgeuses a separate model call to evaluate whether the response is grounded in context — DoorDash's production pattern, now supported natively by Langfuse and Braintrust
- SelfCheckGPT generates multiple responses and checks consistency; semantic entropy across generations serves as a hallucination indicator
The human-in-the-loop pattern that best balances efficiency with safety is draft-and-review: AI generates a grounded response with citations, the draft enters a review queue alongside the original ticket, retrieved context, and confidence score, and a human agent can approve, edit, or reject. Every edit gets logged as training signal, creating a continuous improvement loop where the system learns preferred phrasings and which responses get consistently rejected. Over time, the human override rate should decrease. If it doesn't, the retrieval pipeline needs attention.
The recommended tech stack for zero-hallucination support triage
Choosing the right components at each layer directly impacts hallucination rates. Based on current benchmarks and production evidence through early 2026:
LLMs
Use a tiered approach. Route classification and triage tasks to GPT-4o mini ($0.15/$0.60 per million tokens) or Claude Haiku ($1.00/$5.00) — fast, cheap, and accurate for constrained selection tasks. Route response generation to Claude Sonnet 4 — independent testing shows Claude at a 13% error rateversus GPT-4's 21% and Gemini's 19% in practical applications, and Anthropic's safety-first design philosophy shows in consistently lower hallucination rates. Google's Gemini 2.0 Flash achieves the lowest measured hallucination rate at 0.7%on Vectara's leaderboard and offers the best cost-performance ratio for budget-conscious deployments. Open-source models like Llama 3 and Mistral are appropriate only when data sovereignty requirements mandate self-hosting — they require significantly more guardrail infrastructure.
Vector databases
Pinecone offers the fastest path to production with zero operational burden, SOC 2/HIPAA compliance, and consistent 40–50ms p99 latency. Weaviate provides the best native hybrid search (BM25 plus vector), which directly improves RAG accuracy and reduces hallucinations — the recommended choice when retrieval quality is the top priority. Teams already on PostgreSQL should consider pgvector for datasets under 50 million vectors, eliminating additional infrastructure. Qdrant leads on raw performance (30–40ms p99, up to 15,000 QPS) for self-hosted high-throughput scenarios.
Orchestration
The production-proven pattern combines LlamaIndex for retrieval (optimized RAG with built-in query engines and evaluation) with LangChain for workflow orchestration (multi-step reasoning, tool calling, escalation routing). LlamaIndex handles the knowledge retrieval pipeline where hallucination prevention matters most; LangChain's LangGraph manages the stateful triage workflow. Microsoft-stack teams should use Semantic Kernel; enterprises with strict governance requirements benefit from Haystack by deepset.
Monitoring
Langfuse (open-source, self-hostable, generous free tier) combined with the RAGAS evaluation framework provides comprehensive hallucination tracking. Langfuse traces every prompt, retrieval, and generation; RAGAS scores faithfulness on a sample of production traffic. Helicone adds a lightweight proxy layer for cost tracking and caching. Datadog LLM Observability provides out-of-the-box hallucination detection for enterprises already on the platform, flagging contradictions and unsupported claims automatically. Key alert thresholds: faithfulness score below 0.85, hallucination rate exceeding 5%, human override rate spiking above 30%, or retrieval recall@5 dropping below 0.75.
What the real-world numbers show — and what Klarna's reversal teaches
The companies achieving the strongest results share consistent patterns. Intercom automated 81% of its own support with Fin, saving $7.5–$9 million annually and achieving a 66% average resolution rate across 6,000+ customers. Freshdesk's Freddy AI slashed first-response times from 6+ hours to under 4 minutes and deflected over 50% of retail and travel queries. AssemblyAI reduced first-response time from 15 minutes to 23 seconds — a 97% improvement — using Pylon's AI routing. Unity deflected 8,000 tickets and saved $1.3 million even as volume surged 56%.
But the most instructive case is Klarna. In February 2024, the fintech announced its OpenAI-powered AI assistant handled 2.3 million conversations in its first month — equivalent to 700 full-time agents — cutting resolution time from 11 minutes to 2 minutes and projecting a $40 million profit improvement. By Q3 2025, the system was doing the work of 853 agents and had saved $60 million.
Then the other shoe dropped. CEO Sebastian Siemiatkowski admitted publicly that “cost was a predominant evaluation factor” that led to “lower quality,” and Klarna began rehiring human agents. His reversal crystallized the industry consensus: “In a world of automation, nothing is more valuable than a truly great human interaction.”
Forrester analyst Kate Leggett noted Klarna “overpivoted on their AI strategy,” and her 2026 predictions warn that service quality will dip across the industry as companies wrestle with AI deployment. She predicts about one-third of brands will roll out AI self-service and fail. Gartner's October 2025 survey of 321 service leaders found that over 80% expect to reduce agent headcount — but only 20% have actually done so, and Gartner predicts half of companies that cut staff will rehire by 2027.
The operational benchmarks for well-implemented AI triage are telling: 74% reduction in first-response time (from 8.2 minutes to 2.1 minutes average), 40–60% automatic resolution of B2B tickets, 68% cost reduction per interaction (from $4.60 to $1.45), and an average return of $3.50 for every $1 invested, with top performers reaching 8x ROI. Most organizations realize cost savings within 3–6 months.
Measuring what matters: the metrics that keep hallucinations at zero
Tracking the right KPIs separates systems that maintain zero hallucination tolerance from those that drift into liability. Four categories.
Hallucination and quality metrics
These are the most critical. Track hallucination rate (percentage of responses flagged by automated evaluators — target below 1% for critical customer-facing tasks, with 3% as an acceptable upper bound for RAG-based systems). Monitor RAGAS Faithfulness scores across all generated responses, alerting when the distribution shifts below 0.85. Track confidence score distributions for drift — a gradual shift toward lower confidence indicates knowledge base staleness or query distribution changes. Log human override rate (percentage of AI drafts rejected or heavily edited by agents) — this should decrease over time; sustained rates above 30% indicate a retrieval or generation problem.
Operational metrics
Measure efficiency gains: first-response time, mean time to resolution, ticket deflection rate, escalation rate, and cost per ticket. The industry benchmark for AI-assisted first-response time is under 2 minutes; best-in-class systems achieve sub-30-second responses.
Customer experience metrics
Automation cannot sacrifice satisfaction. Track CSAT specifically for AI-handled versus human-handled tickets (the gap should be minimal). Monitor customer effort score and NPS. Zendesk customer Vagaro achieved 92% CSAT while resolving 44% of requests with AI — demonstrating that well-implemented automation maintains satisfaction. But 86% of customersstill believe empathy and human connection matter more than speed, per Five9's March 2025 survey. Speed without warmth is a false economy.
System health metrics
Catch problems before they reach customers: retrieval recall@5 (are relevant documents appearing in top results?), query rewrite quality, embedding drift, knowledge base coverage gaps, and latency. When hallucinations occur in production, the root cause is almost always retrieval quality — wrong chunks retrieved, relevant chunks missed, or stale content — not the LLM itself. Fix the retrieval pipeline first.
The bottom line
Zero-hallucination support triage is an architecture problem, not a model problem. Classify before you generate. Ground every response in retrieved evidence. Enforce citations. Verify outputs through multiple independent layers. Design the human escalation path before building the automation around it. The companies seeing the strongest results — Intercom's 66% resolution rate, Freshdesk's sub-4-minute response times, AssemblyAI's 97% faster first responses — all share this layered, defense-in-depth approach.
The technology stack has matured enough that the “how” is no longer the hard part. Claude Sonnet and Gemini Flash achieve sub-3% hallucination rates with proper RAG. NeMo Guardrails and Guardrails AI provide production-ready safety layers. RAGAS and Langfuse enable continuous monitoring. The hard part is organizational discipline: maintaining knowledge base quality, logging every human correction as training signal, resisting the pressure to auto-respond when confidence is low, and accepting that the most valuable thing an AI triage system can say is “I don't know — let me connect you with someone who does.” Klarna's $60 million in savings and subsequent quality correction tell the complete story: automation without hallucination guardrails is a liability. Automation with them is transformative.