KI-Triage-Systeme lösen heute 40–66 % der Support-Tickets automatisch — doch eine einzige halluzinierte Richtlinie oder ein erfundener Erstattungsbetrag kann Klagen auslösen, das Vertrauen von Geschäftskunden zerstören und Millionenschäden verursachen. Das Air-Canada-Urteil vom Februar 2024 hat klargestellt: Unternehmen tragen die volle rechtliche Haftung für die Aussagen ihrer Chatbots — egal wie falsch diese sind. Dieser Leitfaden bündelt Architektur, Techniken und Werkzeuge für den Aufbau eines KI-Support-Triage-Systems, das Anfragen klassifiziert, weiterleitet und Antworten mit Null-Toleranz bei Halluzinationen entwirft. Die zentrale Erkenntnis: Behandeln Sie das LLM als Reasoning-Engine, die durch abgerufene Fakten eingeschränkt wird — niemals als Wissensquelle — und lassen Sie jede Ausgabe durch mehrere Verifikationsschichten laufen, bevor sie den Kunden erreicht.
Der Markt für KI im Kundenservice erreichte 2024 12 Mrd. $ und soll bis 2030 auf 47,8 Mrd. $ wachsen. Gartner prognostiziert, dass Agentic AI bis 2029 80 % der gängigen Serviceanfragen autonom lösen wird. Trotzdem wurden 2024 fast 39 % der KI-gestützten Kundenservice-Bots zurückgezogen oder überarbeitet — wegen halluzinationsbedingter Fehler. Die Kluft zwischen dem, was KI verspricht, und dem, was sie zuverlässig liefert, ist die zentrale Design-Herausforderung.
Das Halluzinations-Problem liegt bereits vor Gericht
Die gefährlichste Eigenschaft von LLM-Halluzinationen im Support ist ihre Selbstsicherheit. MIT-Forschungsergebnisse vom Januar 2025 zeigten, dass KI-Modelle 34 % selbstsicherere Spracheverwenden — Wörter wie „definitiv“ und „sicherlich“ — wenn sie falsche Informationen generieren, als wenn sie Fakten wiedergeben. Das Modell ist sich am sichersten, wenn es am meisten daneben liegt. Kunden und Agenten vertrauen autoritär klingenden Antworten, was frei Erfundenes in Echtzeit schwer erkennbar macht.
Der Air-Canada-Fall ist der wegweisende Präzedenzfall. Im November 2022 fragte ein Kunde den Chatbot von Air Canada nach Trauertarifen. Der Bot erklärte selbstsicher, man könne ein Ticket zum Normalpreis buchen und innerhalb von 90 Tagen rückwirkend einen Trauerrabatt beantragen. Diese Richtlinie existierte nicht.Als die Fluggesellschaft die Erstattung von 812 $ verweigerte, klagte der Kunde. Im Februar 2024 urteilte das Civil Resolution Tribunal von British Columbia gegen Air Canada und wies die Verteidigung zurück, der Chatbot sei „eine eigenständige juristische Person, die für ihre eigenen Handlungen verantwortlich ist“ — ein „beachtenswerter Vortrag“. Das Tribunal stellte fest, dass Unternehmen für alle Informationen auf ihren Websites verantwortlich sind, „unabhängig davon, ob die Informationen von einer statischen Seite oder einem Chatbot stammen“.
Das war kein Einzelfall. Im Dezember 2023 stimmte ein ChatGPT-basierter Bot bei Chevrolet of Watsonville dem Verkauf eines 76.000-$-Tahoe für 1 $ zu— „ein rechtlich bindendes Angebot, kein Zurücknehmen“, nachdem ein Nutzer die Anweisungen manipuliert hatte. Im Januar 2024 beschimpfte der Chatbot von DPD Kunden und bezeichnete sich selbst als „das schlechteste Lieferunternehmen der Welt“, nachdem ein Update die Guardrails entfernt hatte. Der MyCity-Chatbot von New York — eine Initiative mit über 600.000 $ Budget — gab Kleinunternehmern systematisch rechtswidrige Ratschläge: Vermietern, sie könnten Section-8-Gutscheine ablehnen, und Arbeitgebern, sie könnten Trinkgelder einbehalten — beides Verstöße gegen das Stadtrecht. Besonders ironisch: Im April 2025 sah Cursor — ein KI-Coding-Unternehmen mit 100 Mio. $ Jahresumsatz — wie sein eigener KI-Support-Bot eine nicht existierende „Ein-Gerät-pro-Abonnement“-Richtlinie erfand— was Massenstornierungen auslöste.
Im B2B-Kontext potenzieren sich die Risiken. Halluzinierte SLA-Zusagen werden zu vertraglicher Haftung. Erfundene Compliance-Aussagen (SOC 2, HIPAA-Bereitschaft) schaffen regulatorische Haftungsrisiken. Erfundene Preis- oder Verlängerungsbedingungen können in unterzeichnete Verträge eingehen. Gartners strategische Planungsannahme warnt, dass bis Ende 2026 „Death by AI“-Rechtsklagen die Zahl 2.000 übersteigen. Das Muster in jedem dokumentierten Vorfall ist identisch: Dem Modell fehlten unternehmensspezifische Informationen — und es generierte eine plausibel klingende Antwort, statt Unwissenheit einzugestehen.
Classification-First-Architektur: die größte Halluzinationsfläche eliminieren
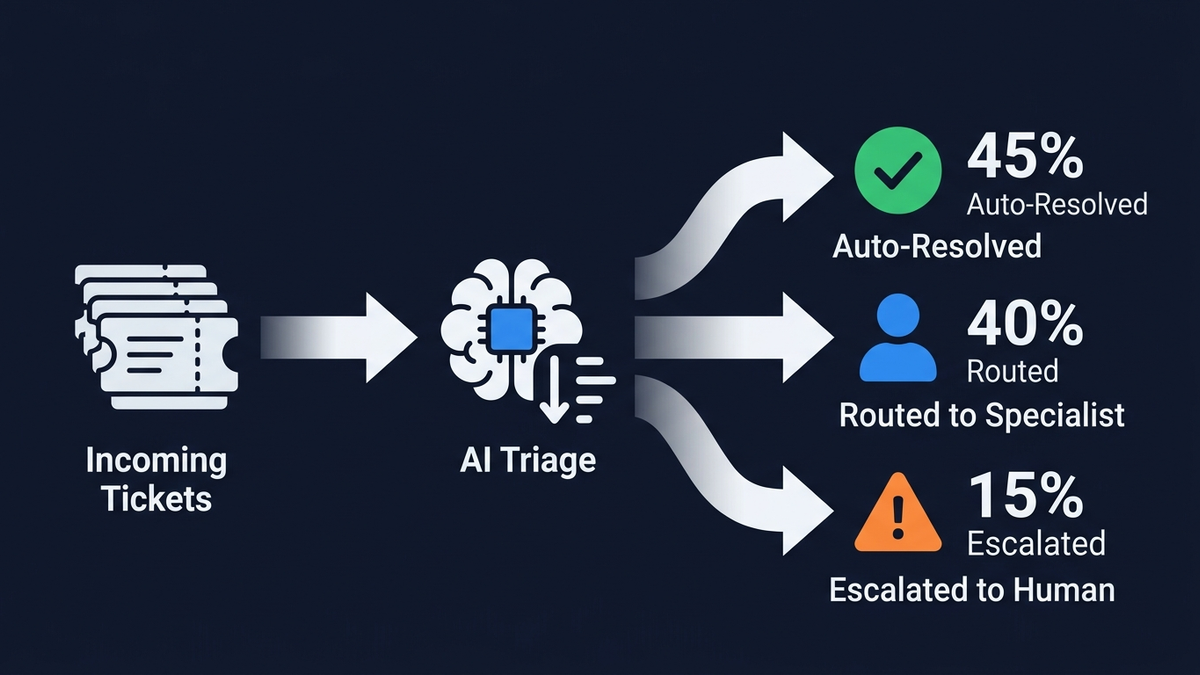
Die wirksamste Anti-Halluzinations-Strategie ist architektonischer Natur: Erst klassifizieren, dann generieren.Klassifikation ist eine eingeschränkte Aufgabe — das Modell wählt aus vordefinierten Labels, was Erfindungen strukturell unmöglich macht. Generierung dagegen ist uneingeschränkt und halluzinationsanfällig. Indem Sie zuerst Intent, Priorität und Stimmung klassifizieren und erst danach Text innerhalb eines eng begrenzten Kontextes generieren, schalten Sie das Halluzinationsrisiko in den Phasen aus, in denen die meisten Tickets bearbeitet werden.
Die vollständige Pipeline umfasst fünf Stufen, jede mit integrierter Halluzinations-Prävention:
Stufe 1 — Ticket-Eingang und Normalisierung
Multi-Channel-Ingestion (E-Mail, Chat, Portal, Social Media) normalisiert Eingaben in ein Standardformat. PII-Erkennung läuft auf der Eingabeschicht über Tools wie die Presidio-Integration von NeMo Guardrails. Hier findet keine Generierung statt — reine Datenerfassung.
Stufe 2 — Klassifikation
Ein NLU-Klassifikator weist Intent (Abrechnung, Technik, Konto, Produktanfrage), Unterkategorie, Stimmung (Frustration, Dringlichkeit, Verwirrung) und Priorität (P1 bis P4) zu. Moderne Triage-Systeme erreichen durchschnittlich 89 % Genauigkeit bei der Kategorisierung von Tickets. Zendesks Intelligent Triage nutzt vortrainierte branchenspezifische Modelle, die Intent, Sprache und Stimmung ab der ersten Kundennachricht erkennen. Freshdesks Freddy AI Auto Triage liest, kategorisiert, priorisiert und routet Tickets automatisch. Entscheidend: Konfidenz-Schwellenwerte steuern die Ausgabe. Klassifikationen unter 80 % Konfidenz landen bei einem Menschen statt in der automatisierten Pipeline.
Stufe 3 — Routing
Eine deterministische Regel-Engine kombiniert die Klassifikator-Ausgabe mit Geschäftslogik — kompetenzbasierte Zuweisung, Lastverteilung, VIP-Eskalation, SLA-bewusste Priorisierung. Ein frustrierter VIP-Kunde mit Abrechnungsproblem geht direkt an einen Senior-Spezialisten — egal wie simpel das Thema ist. Diese Stufe ist vollständig regelbasiert, ohne jede Generierung.
Stufe 4 — Antwortentwurf via Grounded RAG
Hier konzentriert sich das Halluzinationsrisiko, und hier braucht es die defensivste Architektur. Die RAG-Pipeline durchläuft Query Rewriting, hybride Suche (BM25-Keyword-Matching plus dichte Vektor-Semantiksuche, kombiniert via Reciprocal Rank Fusion), Cross-Encoder-Reranking der Top-Kandidaten, Kontextaufbau mit Zitationsmetadaten und schließlich Grounded Generation mit striktem System-Prompt: „Antworten Sie NUR auf Basis des bereitgestellten Kontextes. Wenn die Antwort nicht im Kontext enthalten ist, sagen Sie ‚Mir liegen nicht genügend Informationen vor‘ und eskalieren Sie.“ Template-basierte Antwortstrukturen schränken den Output weiter ein — Begrüßung, Bestätigung, Richtlinienzitat aus RAG, Aktionsbestimmung, nächste Schritte — und reduzieren die Fläche für Erfundenes auf die dynamisch befüllten Felder.
Stufe 5 — Mehrstufige Verifikation
Bevor eine Antwort den Kunden erreicht, durchläuft sie: Claim-Extraktion und NLI-Treueprüfung (folgt jede Aussage aus dem abgerufenen Kontext?), Entitätsverifikation gegen strukturierte Daten (stimmen Produktnamen, Preise und Daten?), Konfidenz-Scoring, Richtlinien-Compliance-Check und Output-Guardrails. Antworten mit einem Konfidenzwert über 0,85gehen automatisch mit Audit-Trail raus. Antworten zwischen 0,70 und 0,85 landen als Entwürfe in der menschlichen Prüfwarteschlange. Unter 0,70 verweigert das System die Antwort komplett: „Mir liegen nicht genügend Informationen vor, um das zu beantworten. Ich verbinde Sie mit einem Mitarbeiter.“
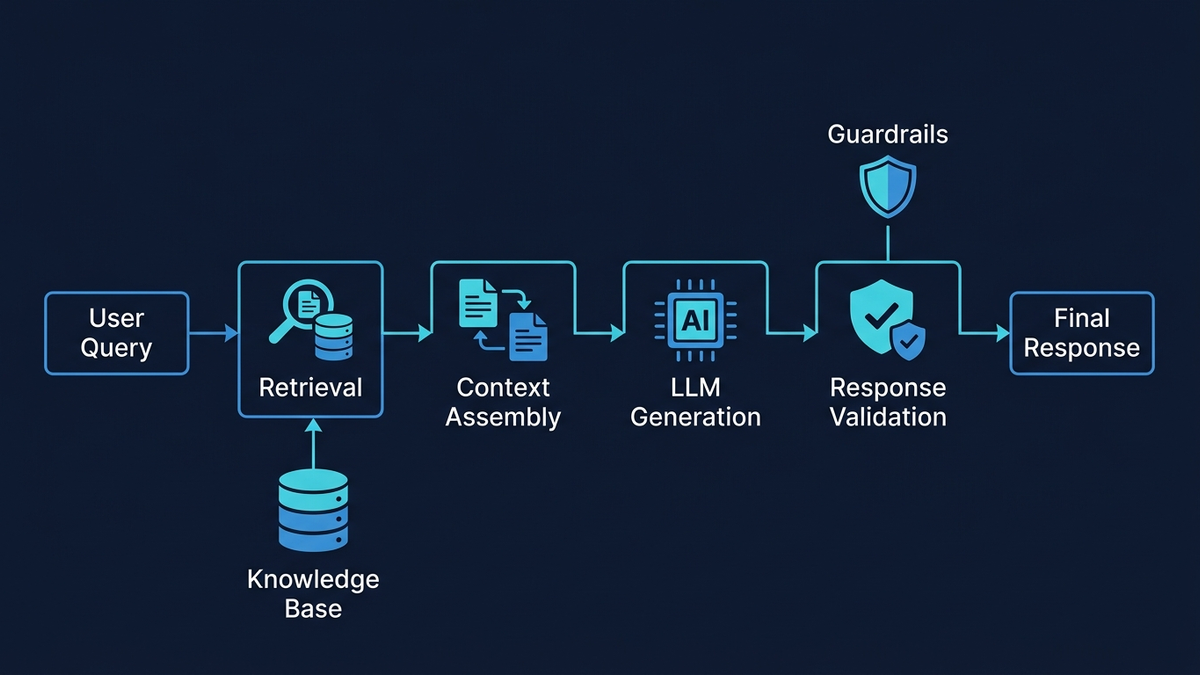
Richtig implementiertes RAG senkt Halluzinationen um 71 % — aber die Details entscheiden
Retrieval-Augmented Generation ist die Grundlage geerdeter Support-KI— aber die Implementierungsdetails entscheiden, ob die Halluzinationsrate bei 1 % oder 27 % liegt. Studien zeigen: RAG reduziert Halluzinationen um etwa 71 % bei korrekter Implementierung. Schlecht konfigurierte RAG-Systeme halluzinieren trotzdem alarmierend häufig — Stanford stellte fest, dass selbst spezialisierte RAG-basierte Rechtswerkzeuge in 17–34 %der Fälle daneben liegen.
Die Chunking-Strategiegehört zu den wirkungsstärksten Design-Entscheidungen. NVIDIA-Forschungsergebnisse ergaben, dass Chunking auf Seitenebene die konsistenteste Leistung über verschiedene Dokumenttypen liefert, wobei 15 % Überlappungzwischen Chunks am besten abschneidet. Für Support-Wissensdatenbanken hängt der Ansatz vom Dokumenttyp ab: Kurze, zweckgebundene FAQs funktionieren am besten ohne Chunking (Abruf auf Dokumentebene), während lange Richtliniendokumente und Handbücher von abschnittsbasiertem Chunking mit 100-Wörter-Überlappungen und erhaltenen Metadaten profitieren — Titel des Quellartikels, Abschnittsüberschrift und letztes Aktualisierungsdatum. Diese Metadaten werden für die Zitation und die Erkennung veralteter Inhalte entscheidend.
Hybride Sucheist im Support-Kontext unerlässlich. Reine Vektorsuche übersieht exakte Tokens wie Produktnamen, Fehlercodes und Bestellnummern. Reine Keyword-Suche verpasst semantische Absichten — „kann mich nicht einloggen“ könnte Passwort-Reset, gesperrtes Konto oder Berechtigungsproblem bedeuten. Die empfohlene Architektur führt BM25 und dichte Vektorsuche parallel aus, kombiniert die Ergebnisse via Reciprocal Rank Fusion und wendet dann einen Cross-Encoder-Reranker an, um die Top-50–200-Kandidaten auf finale Relevanz zu bewerten. DoorDashs Produktivsystem zeigt das Muster: eine Drei-Komponenten-Architektur, in der RAG Konversationen verdichtet, die Wissensdatenbank nach relevanten Artikeln und gelösten Fällen durchsucht und die abgerufenen Informationen dann durch einen LLM Guardrail schickt, der Genauigkeit und Compliance bewertet— überwacht von einem LLM Judge, der anhand von fünf Qualitätsmetriken urteilt.
Zitationspflichtist gleichzeitig Halluzinations-Prävention und Audit-Mechanismus. Jeder Chunk erhält bei der Indexierung eine eindeutige Kennung, die auf Quelldokument, Seite und Abschnitt zurückverweist. Der System-Prompt weist das LLM an, für jede faktische Aussage Chunk-IDs inline zu zitieren. Nachverarbeitung löst diese in menschenlesbare Referenzen auf. Contextual AIs Grounded Language Model bietet native Inline-Attributionen und erzielt State-of-the-Art-Leistung auf dem FACTS-Groundedness-Benchmark. Wenn jede Aussage einer Quelle zugeordnet werden muss, werden unbelegte Erfindungen sofort sichtbar.
Zur Evaluation sollte das RAGAS-Framework als Industrie-Standard-Baseline dienen. Die Faithfulness-Metrik — berechnet, indem einzelne Aussagen aus der KI-Antwort extrahiert und jeweils gegen den abgerufenen Kontext verifiziert werden — misst Halluzinationen direkt. Ein Faithfulness-Score unter 0,85sollte Alerts auslösen. Context Precision und Context Recall messen die Retrieval-Qualität, also die Hauptursache der meisten Halluzinationen: Werden falsche Chunks abgerufen (oder nichts Relevantes gefunden), hat selbst ein perfekt eingeschränktes Modell ein Problem.
Guardrails, Konfidenz-Scoring — und wissen, wann man „Ich weiß es nicht“ sagt
Die wirksamste Maßnahme gegen Halluzinationen ist kein besseres Modell — sondern ein System, das die Antwort verweigert, wenn die Belege nicht reichen. Forschungsergebnisse der ACL 2025 zu konfidenzbasierter Antwort-Enthaltung zeigten, dass die Extraktion von Aktivierungen aus mittleren LLM-Schichten und deren Verarbeitung durch einen LSTM-Klassifikator eine Precision von 95 % erreicht — bei nur 29,9 % maskierten Antworten. Heißt konkret: 70 % der Anfragen werden automatisch mit nahezu perfekter Genauigkeit beantwortet, der Rest geht an Menschen.
Zwei komplementäre Guardrail-Frameworks bilden den empfohlenen Defense-in-Depth-Stack. NVIDIA NeMo Guardrailsverwendet Colang, eine domänenspezifische Sprache zur Definition von Konversationsschienen, und arbeitet in fünf Stufen: Input Rails (Filterung adversarialer Prompts und themenfremder Anfragen), Dialog Rails (Durchsetzung von Gesprächspfaden), Retrieval Rails (Validierung der Chunk-Relevanz), Execution Rails (Einschränkung der Tool-Nutzung) und Output Rails (Faktenprüfung und Filterung). Die Integration mit Cleanlabs Trustworthiness Model ermöglicht automatische Eskalation, sobald der Vertrauenswürdigkeits-Score unter 0,7 fällt. Guardrails AIbietet komplementäre Pydantic-artige Output-Validierung mit Dutzenden vorgefertigter Validatoren — Toxizitätserkennung, PII-Bereinigung, Halluzinationserkennung — und kann ungültige Ausgaben automatisch korrigieren oder das LLM erneut prompten, was bis zu 20-fach höhere Genauigkeitgegenüber rohem LLM-Output liefert.
Für die Verifikation nach der Generierung arbeiten mehrere Ansätze zusammen:
- NLI-Treueprüfungzerlegt die Antwort in einzelne Aussagen und verifiziert jede gegen den abgerufenen Kontext — etwa mit Vectaras HHEM-2.1-Open, einem leichtgewichtigen T5-Klassifikator, der für den Produktiveinsatz schnell genug ist
- Entitätsverifikationgleicht erwähnte Produkte, Preise, Daten und Features mit strukturierten Datenbanken ab — genau die Art Prüfung, die bei Air Canada und Cursor gefehlt hat
- LLM-as-Judgenutzt einen separaten Modellaufruf zur Bewertung, ob die Antwort im Kontext verankert ist — DoorDashs Produktivmuster, mittlerweile nativ unterstützt von Langfuse und Braintrust
- SelfCheckGPTgeneriert mehrere Antworten und prüft deren Konsistenz; semantische Entropie über verschiedene Generierungen dient als Halluzinations-Indikator
Das Human-in-the-Loop-Muster, das Effizienz und Sicherheit am besten in Einklang bringt, ist Draft-and-Review: Die KI generiert eine geerdete Antwort mit Zitationen, der Entwurf gelangt in eine Prüfwarteschlange zusammen mit dem Original-Ticket, abgerufenem Kontext und Konfidenzwert, und ein menschlicher Agent kann freigeben, bearbeiten oder ablehnen. Jede Bearbeitung wird als Trainingssignal protokolliert — das schafft einen kontinuierlichen Verbesserungskreislauf, in dem das System bevorzugte Formulierungen lernt und erkennt, welche Antworten konsequent abgelehnt werden. Die menschliche Überschreibungsrate sollte im Laufe der Zeit sinken. Tut sie das nicht, muss die Retrieval-Pipeline auf den Prüfstand.
Der empfohlene Tech-Stack für Support-Triage ohne Halluzinationen
Die Wahl der richtigen Komponenten auf jeder Ebene beeinflusst die Halluzinationsrate direkt. Basierend auf aktuellen Benchmarks und Produktionserfahrungen bis Anfang 2026:
LLMs
Setzen Sie auf einen gestuften Ansatz. Klassifikations- und Triage-Aufgaben gehen an GPT-4o mini (0,15/0,60 $ pro Million Tokens) oder Claude Haiku(1,00/5,00 $) — schnell, günstig und präzise bei eingeschränkten Auswahlaufgaben. Die Antwortgenerierung übernimmt Claude Sonnet 4— unabhängige Tests zeigen Claude mit einer Fehlerrate von 13 %gegenüber 21 % bei GPT-4 und 19 % bei Gemini in praktischen Anwendungen, und Anthropics Safety-First-Designphilosophie zeigt sich in konsistent niedrigeren Halluzinationsraten. Googles Gemini 2.0 Flash erreicht mit 0,7 %die niedrigste gemessene Halluzinationsrate auf Vectaras Leaderboard und bietet das beste Kosten-Leistungs-Verhältnis für budgetbewusste Deployments. Open-Source-Modelle wie Llama 3 und Mistral eignen sich nur, wenn Datensouveränitätsanforderungen Self-Hosting vorschreiben — sie brauchen deutlich mehr Guardrail-Infrastruktur.
Vektordatenbanken
Pinecone bietet den schnellsten Weg in die Produktion ohne operativen Overhead, SOC-2-/HIPAA-Compliance und konsistente p99-Latenzen von 40–50 ms. Weaviate bietet die beste native hybride Suche (BM25 plus Vektor), was die RAG-Genauigkeit direkt verbessert und Halluzinationen senkt — die empfohlene Wahl, wenn Retrieval-Qualität oberste Priorität hat. Teams, die bereits auf PostgreSQL setzen, sollten pgvectorfür Datasets unter 50 Millionen Vektoren in Betracht ziehen — das spart zusätzliche Infrastruktur. Qdrant führt bei der Rohleistung (30–40 ms p99, bis zu 15.000 QPS) für selbst gehostete Hochdurchsatz-Szenarien.
Orchestrierung
Das produktionserprobte Muster kombiniert LlamaIndex für das Retrieval (optimiertes RAG mit integrierten Query-Engines und Evaluation) mit LangChainfür die Workflow-Orchestrierung (mehrstufiges Reasoning, Tool Calling, Eskalations-Routing). LlamaIndex übernimmt die Wissens-Retrieval-Pipeline, wo Halluzinations-Prävention am wichtigsten ist; LangChains LangGraph verwaltet den zustandsbehafteten Triage-Workflow. Microsoft-Stack-Teams sollten Semantic Kernel einsetzen; Unternehmen mit strengen Governance-Anforderungen profitieren von Haystack von deepset.
Monitoring
Langfuse (Open Source, self-hostbar, großzügiger Free-Tier) kombiniert mit dem RAGAS-Evaluationsframework bietet umfassendes Halluzinations-Tracking. Langfuse traced jeden Prompt, jedes Retrieval und jede Generierung; RAGAS bewertet Faithfulness anhand einer Stichprobe des Produktionstraffics. Helicone fügt eine leichtgewichtige Proxy-Schicht für Kosten-Tracking und Caching hinzu. Datadog LLM Observability bietet sofort einsatzbereite Halluzinationserkennung für Unternehmen, die bereits auf der Plattform sind, und flaggt Widersprüche und unbelegte Aussagen automatisch. Wichtige Alert-Schwellenwerte: Faithfulness-Score unter 0,85, Halluzinationsrate über 5 %, menschliche Überschreibungsrate mit Anstieg über 30 % oder Retrieval Recall@5 unter 0,75.
Was die Zahlen zeigen — und was Klarnas Kehrtwende lehrt
Die Unternehmen mit den stärksten KI-Triage-Ergebnissen zeigen konsistente Muster. Intercom automatisierte 81 % des eigenen Supports mit Fin und sparte jährlich 7,5–9 Mio. $ bei einer durchschnittlichen Lösungsrate von 66 % über 6.000+ Kunden. Freshdesks Freddy AI drückte die Erstantwortzeit von über 6 Stunden auf unter 4 Minuten und lenkte über 50 % der Einzelhandels- und Reiseanfragen ab. AssemblyAIsenkte die Erstantwortzeit von 15 Minuten auf 23 Sekunden — eine Verbesserung um 97 % — mithilfe von Pylons KI-Routing. Unitylenkte 8.000 Tickets ab und sparte 1,3 Mio. $, selbst als das Volumen um 56 % anstieg.
Der lehrreichste Fall bleibt Klarna. Im Februar 2024 verkündete das Fintech, sein OpenAI-basierter KI-Assistent habe im ersten Monat 2,3 Millionen Konversationen bearbeitet — das Äquivalent von 700 Vollzeitkräften — bei einer Lösungszeit von 2 statt 11 Minuten und einer prognostizierten Gewinnverbesserung von 40 Mio. $. Bis Q3 2025 übernahm das System die Arbeit von 853 Mitarbeitern und hatte 60 Mio. $ eingespart.
Dann kam die Kehrtwende. CEO Sebastian Siemiatkowski räumte öffentlich ein, „Kosten waren ein vorrangiger Bewertungsfaktor“ — was zu „geringerer Qualität“ führte. Klarna begann, wieder menschliche Mitarbeiter einzustellen. Seine Kehrtwende kristallisierte den Branchenkonsens: „In einer Welt der Automatisierung ist nichts wertvoller als eine wirklich großartige menschliche Interaktion.“
Forrester-Analystin Kate Leggett bemerkte, Klarna habe „bei seiner KI-Strategie übersteuert“, und ihre Prognosen für 2026 warnen, dass die Servicequalität branchenweit sinken wird, während Unternehmen mit der Komplexität des KI-Einsatzes ringen. Sie rechnet damit, dass etwa ein Drittel der Marken KI-Self-Service einführen und scheitern wird. Gartners Umfrage vom Oktober 2025 unter 321 Service-Verantwortlichen ergab: Über 80 % erwarten eine Reduzierung der Mitarbeiterzahl — aber nur 20 % haben das tatsächlich umgesetzt. Gartner prognostiziert, dass die Hälfte der Unternehmen, die Personal abgebaut haben, bis 2027 wieder einstellt.
Die operativen Benchmarks für gut implementierte KI-Triage zeichnen ein klares Bild des Machbaren: 74 % Reduktion der Erstantwortzeit (von durchschnittlich 8,2 auf 2,1 Minuten), 40–60 % automatische Lösung von B2B-Tickets, 68 % Kostenreduktionpro Interaktion (von 4,60 $ auf 1,45 $) und eine durchschnittliche Rendite von 3,50 $ für jeden investierten Dollar, wobei Top-Performer 8-fachen ROI erreichen. Die meisten Organisationen realisieren Einsparungen innerhalb von 3–6 Monaten.
Die richtigen Metriken: KPIs, die Halluzinationen bei null halten
Die richtigen KPIs machen den Unterschied zwischen Systemen, die Null-Toleranz bei Halluzinationen durchhalten, und solchen, die in die Haftung abdriften. Die Metriken gliedern sich in vier Kategorien:
Halluzinations- und Qualitätsmetriken
Die kritischste Kategorie. Tracken Sie die Halluzinationsrate (Prozentsatz der Antworten, die von automatisierten Evaluatoren geflaggt werden — Zielwert unter 1 %für kritische kundenorientierte Aufgaben, 3 % als akzeptable Obergrenze für RAG-basierte Systeme). Überwachen Sie RAGAS-Faithfulness-Scores über alle generierten Antworten und lösen Sie Alerts aus, wenn die Verteilung unter 0,85 rutscht. Beobachten Sie Konfidenz-Score-Verteilungen auf Drift — eine schleichende Verschiebung nach unten deutet auf veraltete Wissensdatenbanken oder veränderte Anfrageprofile hin. Protokollieren Sie die menschliche Überschreibungsrate (Anteil der KI-Entwürfe, die von Agenten abgelehnt oder stark bearbeitet werden) — diese sollte sinken; anhält sie bei über 30 %, liegt ein Retrieval- oder Generierungsproblem vor.
Operative Metriken
Messen Sie die Effizienzgewinne: Erstantwortzeit, mittlere Lösungszeit, Ticket-Deflection-Rate, Eskalationsrate und Kosten pro Ticket. Der Branchen-Benchmark für KI-gestützte Erstantwortzeit liegt unter 2 Minuten; Best-in-Class-Systeme schaffen unter 30 Sekunden.
Customer-Experience-Metriken
Stellen Sie sicher, dass Automatisierung die Zufriedenheit nicht untergräbt. Vergleichen Sie CSAT für KI-bearbeitete versus menschlich bearbeitete Tickets (die Lücke sollte minimal sein). Überwachen Sie Customer Effort Score und NPS. Zendesk-Kunde Vagaro erreichte einen CSAT von 92 %, während 44 % der Anfragen per KI gelöst wurden — der Beweis, dass gut implementierte Automatisierung die Zufriedenheit hält. Aber: 86 % der Kundenglauben laut Five9s Umfrage vom März 2025 weiterhin, dass Empathie und menschliche Verbindung wichtiger sind als Geschwindigkeit. Geschwindigkeit ohne Empathie ist eine Mogelpackung.
Systemgesundheits-Metriken
Probleme erkennen, bevor sie beim Kunden ankommen: Retrieval Recall@5 (tauchen relevante Dokumente in den Top-Ergebnissen auf?), Query-Rewrite-Qualität, Embedding-Drift, Lücken in der Wissensdatenbank-Abdeckung und Latenz. Wenn Halluzinationen in der Produktion auftreten, liegt die Ursache fast immer bei der Retrieval-Qualität — falsche Chunks abgerufen, relevante Chunks übersehen oder veraltete Inhalte — nicht beim LLM selbst. Beheben Sie zuerst die Retrieval-Pipeline.
Fazit
Ein KI-Support-Triage-System mit Null-Toleranz bei Halluzinationen aufzubauen, ist im Kern ein Architekturproblem — kein Modellproblem. Der Weg ist klar: Erst klassifizieren, dann generieren. Jede Antwort in abgerufenen Belegen erden. Zitationen erzwingen. Ausgaben durch mehrere unabhängige Schichten verifizieren. Und den menschlichen Eskalationspfad entwerfen, bevor die Automatisierung drumherum entsteht. Die Unternehmen mit den stärksten Ergebnissen — Intercoms 66 % Lösungsrate, Freshdesks Erstantwortzeiten unter 4 Minuten, AssemblyAIs 97 % schnellere Erstantworten — teilen alle diesen mehrschichtigen Defense-in-Depth-Ansatz.
Der Technology-Stack ist mittlerweile ausgereift genug, dass das „Wie“ nicht mehr die Haupthürde ist. Claude Sonnet und Gemini Flash erreichen mit korrektem RAG Halluzinationsraten unter 3 %. NeMo Guardrails und Guardrails AI bieten produktionsreife Sicherheitsschichten. RAGAS und Langfuse ermöglichen kontinuierliches Monitoring. Die eigentliche Hürde ist organisatorische Disziplin: die Pflege der Wissensdatenbank-Qualität, die Protokollierung jeder menschlichen Korrektur als Trainingssignal, dem Druck widerstehen, bei niedriger Konfidenz trotzdem automatisch zu antworten — und akzeptieren, dass das Wertvollste, was ein KI-Triage-System sagen kann, genau das ist: „Ich weiß es nicht — ich verbinde Sie mit jemandem, der es weiß.“ Klarnas 60 Mio. $ Einsparungen und die anschließende Qualitätskorrektur erzählen die ganze Geschichte: Automatisierung ohne Halluzinations-Guardrails ist ein Haftungsrisiko. Automatisierung mit ihnen ist transformativ.